MCP from First Principles to Production: Why JSON-RPC over stdio beat WebSockets + OpenAPI
Developers who have used at least one LLM API (Claude, GPT, Gemini) and want to build production-grade integrations using MCP. Familiar with REST APIs, basic auth flows, and terminal-driven workflows.
- Explain WHY MCP chose JSON-RPC over stdio instead of WebSockets or a REST+OpenAPI approach — and when that choice matters for your own architecture
- Read and write a complete MCP server from scratch, handling the full JSON-RPC lifecycle over stdio and HTTP streaming
- Choose the right MCP primitive (Tool, Resource, or Prompt) for any integration requirement with a written decision rule
- Wire up OAuth 2.1 + DPoP auth on an MCP server so it rejects unauthorized requests and produces a full audit trail
- Deploy an MCP server behind a gateway to a team of 1,000 users with structured logs, RBAC, and zero-downtime rollout
Why MCP exists — the design problem it actually solves
The Model Context Protocol (MCP) standardises how AI applications connect to data sources and tools via JSON-RPC 2.0 over stdio or HTTP.[1]
Most tutorials show basic SDK examples. This chapter explains why the protocol is shaped as it is: the design constraints, rejected alternatives, and explicit out-of-scope problems. Understanding the why turns the specification from an arbitrary list of choices into a logical, necessary framework.
Key facts
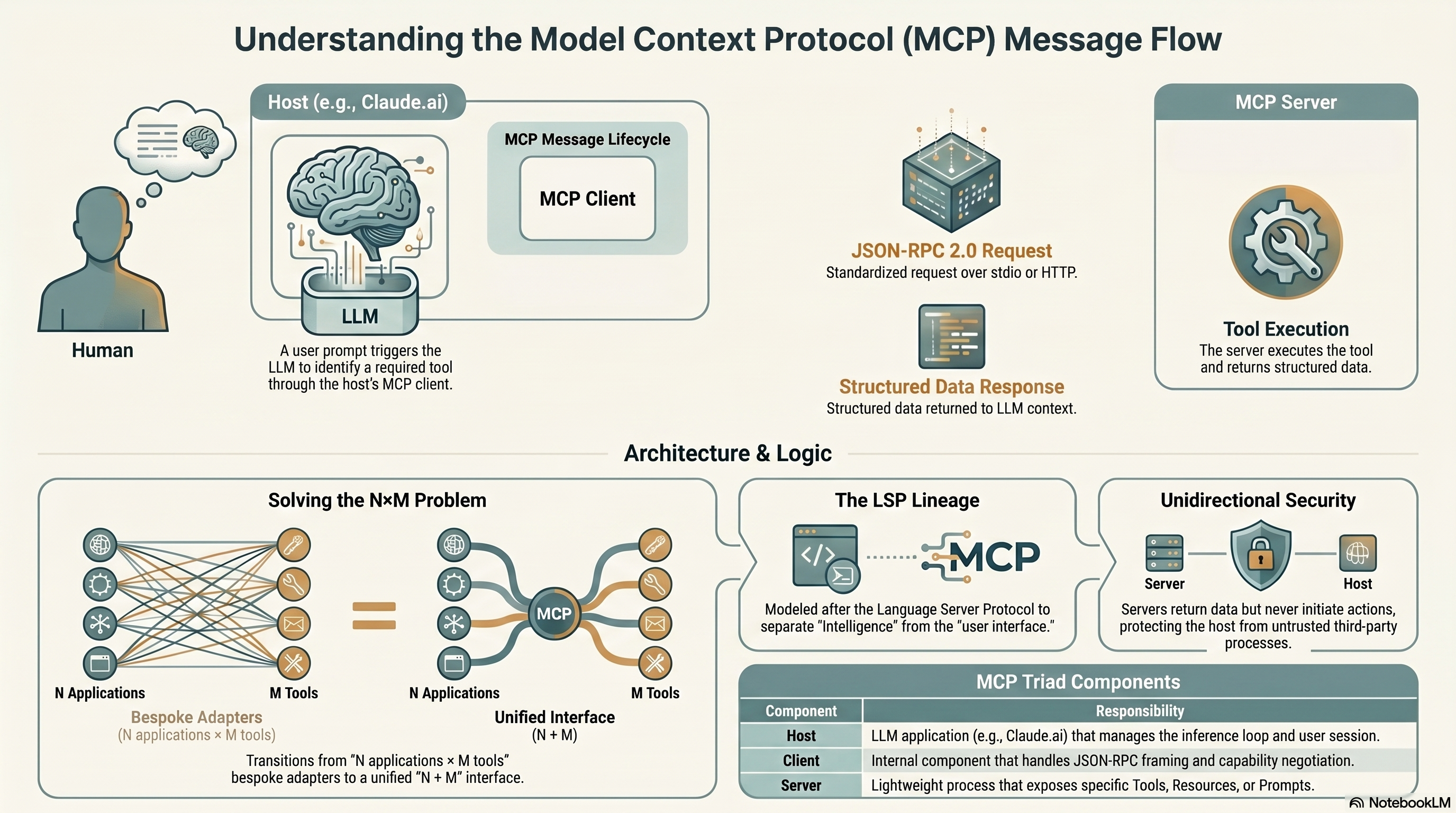
- Announced: 25 November 2024 by Anthropic.[1]
- Wire protocol: JSON-RPC 2.0 (newline-delimited) over stdio or HTTP+SSE.[1]
- Primitives: Tools, Resources, Prompts.[1]
- LSP lineage: Modelled on the Language Server Protocol.[3]
- Auth trajectory: OAuth 2.1 + DPoP token binding in roadmap.[2]
- Governance: Apache 2.0; Anthropic chairs, no exclusive authority.
The N×M integration problem
Before MCP existed, every team building an LLM application faced the same structural trap.
- Every LLM application team independently wrote bespoke adapters for each external tool, producing N×M incompatible implementations with no shared protocol layer.
- The N×M explosion is structurally identical to problems previously solved in compiler design (LLVM IR) and video codec support — in each case, inserting a standard protocol reduced N×M connections to N+M.
- MCP's value proposition is that a single shared protocol turns 24 custom adapters (4 apps × 6 tools) into 10 pieces (4 clients + 6 servers).
Suppose you are building an AI coding assistant. Your users need the model to read GitHub repos, query Jira tickets, pull documentation from Confluence, run tests in CI, and check Datadog metrics. That's five integrations. Each integration requires: understanding the third-party API, writing an adapter that maps the API's response shape to whatever JSON structure your model prefers, handling auth (likely OAuth for each service), dealing with pagination, and managing error recovery. Each adapter is bespoke code that belongs to your application and nobody else's.
Now suppose a second team is building an AI support agent. They need the same five integrations plus Salesforce and Zendesk. They repeat the work. A third team building an AI DevOps assistant needs most of the same integrations again. The result is N applications × M tools = N×M integrations, each implemented slightly differently, each with its own bugs, its own auth model, and its own failure modes.
This isn't a hypothetical. In the period leading up to MCP's launch, teams building on Claude and other LLMs had each written bespoke integration adapters for every tool they needed — a landscape of redundant, incompatible implementations, each solving the same underlying problem in isolation.[1] Every major LLM provider observed the same fragmentation pattern. The ecosystem was splitting along exactly the axis that makes tooling ecosystems fail: each participant solving the same local problem independently, without a shared protocol layer.
The textbook fix for N×M proliferation is to insert a standard: instead of N×M direct connections, you get N+M relationships to a common interface. That is exactly what MCP does for LLM tool integrations.
Three alternatives that didn't survive contact with reality
The N×M framing explains that a protocol was needed. It doesn't explain why MCP looks the way it does. For that, you need to understand what was rejected and why.
- Custom REST adapters fail for LLM tool calls because REST assumes long-lived sessions and human-in-the-loop re-authentication, while LLM tool calls are ephemeral and programmatic.
- WebSocket hubs introduce a stateful single point of failure and require network reachability that makes local-process tools impractical.
- OpenAPI describes what an API does but lacks semantics for streaming, capability negotiation, and structured error typing that LLMs need to reason about failures.
Alternative 1: Custom REST adapters Failure mode: REST APIs assume long-lived HTTP, human-like error handling, and stable sessions. LLM tool calls are ephemeral, parallel, and programmatic — there's no human in the loop to re-authenticate when a token expires. Bespoke adapters fail silently, and code is never reusable across applications.
Alternative 2: WebSocket hub Failure mode: WebSocket hubs are stateful and complex, becoming a single point of failure that degrades all connected applications simultaneously. They also require network reachability, which is a security and operational headache for local-process tools that stdio handles natively.
Alternative 3: OpenAPI spec passthrough Failure mode: OpenAPI describes what an API does, not how an LLM should call it. It lacks semantics for streaming, capability negotiation, and structured error typing that LLMs need to reason about failures. Raw HTTP error codes provide no context for model-driven recovery.
I want to understand the N×M problem concretely. Without any standard protocol: if I have 4 LLM applications (a coding assistant, a support agent, a data analyst tool, and a DevOps helper) and each ne…
Show expected output
Without a standard protocol, you need 4 × 6 = 24 integration adapters — each application writes its own connector to each tool. With a standard protocol like MCP: - Each of the 6 tools publishes 1 MCP server (6 total) - Each of the 4 applications implements 1 MCP client (4 total) - Total integration surface: 6 + 4 = 10 pieces, not 24 The trade-offs: (1) Protocol overhead — every call goes through JSON-RPC framing and capability negotiation. (2) Least-common-denominator risk — the protocol must be general enough for all tools. (3) Versioning coupling — spec changes require both clients and servers to update. (4) Discovery bootstrapping — you need a way for applications to find servers, which the 2026 roadmap solves with .well-known gateway metadata. The trade-off is worth it once N and M are both greater than ~3.
The LSP lineage: a protocol that solved this before
The Model Context Protocol did not invent its own design. It borrowed from a protocol that already solved the identical N×M problem in a different domain: the Language Server Protocol (LSP), introduced by Microsoft in 2016.[3]
- LSP solved the M-editors × N-languages explosion by separating language intelligence from editor UI, enabling any LSP client to talk to any language server via a standard JSON-RPC protocol.
- MCP directly borrows three LSP architectural choices: JSON-RPC 2.0 over stdio, capability negotiation at handshake time, and a stateful session model.
- The stateful session model contrasts with REST's stateless design, allowing servers to maintain context (open DB connections, cached auth tokens) between calls in a session without re-establishing it per request.
Before LSP, every code editor (VS Code, Vim, Emacs, Eclipse, IntelliJ) had to implement language support for every programming language — syntax highlighting, go-to-definition, autocomplete, rename refactor. The result was the same N×M explosion: M editors × N languages = M×N implementations, each with different quality and feature parity.
LSP solved it with a single insight: separate the language intelligence from the editor UI. A language server runs as a local process and speaks a standard JSON-RPC protocol. Any editor that implements the LSP client can talk to any language server. Today, the Python LSP server (pylsp) works identically in VS Code, Neovim, Emacs, and Helix. The editor teams wrote one client; the language teams wrote one server.
MCP borrows three specific architectural choices from LSP:
1. JSON-RPC 2.0 over stdio for local servers. LSP uses JSON-RPC over stdio for local servers. MCP uses exactly the same wire format for the same reason: it's a self-contained framing protocol, easy to parse, with no external dependencies. A process that reads from stdin and writes to stdout is the simplest possible IPC primitive — no sockets, no shared memory, no OS-specific APIs.[1][4]
2. Capability negotiation at handshake time. LSP's initialize / initialized handshake lets the client and server advertise which features each supports before any work begins. MCP's initialize lifecycle follows the same pattern: the client sends its capabilities, the server responds with its own, and both parties agree on the protocol version. This means a new client can talk to an old server (or vice versa) without crashing — they negotiate down to the intersection of their capabilities.[1]
3. Stateful session model. LSP maintains a session per open project. MCP maintains a session per connected client. Both sessions are terminated when the process exits or the connection closes. This is in contrast to REST APIs, which are stateless by design. The stateful model allows MCP servers to maintain context between calls (e.g., an open database connection, a cached authentication token) without re-establishing it on every request.
The explicit LSP comparison appears in the original MCP announcement from Anthropic and in the specification's architecture documentation.[1]
Compare LSP's initialize/initialized handshake with MCP's initialize lifecycle. Walk me through exactly what fields are exchanged in MCP's initialize request and response, and explain what each side l…
Show expected output
MCP's initialize handshake (spec §3.1):
Client → Server (initialize request):
- protocolVersion: the spec version the client supports (e.g. '2024-11-05')
- capabilities: object advertising what the client can handle (roots, sampling)
- clientInfo: { name, version } for diagnostics
Server → Client (initialize response):
- protocolVersion: the version the server will use (must be ≤ client's)
- capabilities: object advertising what the server exposes (tools, resources, prompts, logging)
- serverInfo: { name, version } for diagnostics
Client → Server (notifications/initialized): confirms the client is ready.
What each side learns that a REST /health check cannot tell you:
1. Protocol version compatibility — the client knows immediately whether the server speaks a version it understands. A /health endpoint returns 200 OK regardless of spec version.
2. Capability surface — the client learns exactly which primitives (tools/resources/prompts) the server supports before making a single call. No trial-and-error.
3. Negotiated version floor — both sides agree on the lowest common version, so neither sends fields the other can't parse.
4. Server identity — serverInfo lets the host log which implementation is running, useful for debugging multi-server setups.
A REST /health check tells you only that the server is alive. MCP's handshake tells you what it can do and whether you can talk to it.The host / client / server triad
MCP defines a precise three-way topology that almost every tutorial glosses over. Understanding it prevents an entire class of architectural mistakes.
- The Host is the LLM application that starts server processes, manages sessions, and decides which tool results to inject into model context — not the server or the client.
- The Client is internal plumbing inside the Host that manages a single server connection; a Host can maintain multiple Clients simultaneously, one per connected server.
- The unidirectional constraint — servers only return data, never initiate actions — is what makes MCP servers safe to run as untrusted third-party processes.
Host — The LLM application. Claude.ai is a host. Cursor is a host. Your custom agent is a host. The host is responsible for: starting and stopping MCP server processes, managing user sessions, holding the LLM inference loop, and deciding which tool results to include in the model's context.
Client — A component inside the host that manages a single MCP server connection. A host can maintain multiple clients simultaneously (one per MCP server). The client handles: JSON-RPC framing, capability negotiation, request multiplexing, and lifecycle management for one server. It is not user-facing; it's plumbing.
Server — The MCP server itself. A server exposes some combination of Tools, Resources, and Prompts, and it serves exactly one domain: a GitHub MCP server knows about repos and files; a Postgres MCP server knows about tables and queries. Servers are intentionally narrow.
The key constraint: the server does not independently trigger host actions. Information flows in one direction: the client calls the server, the server returns results, the client passes them to the host, the host injects them into the model context. While MCP's sampling capability (sampling/createMessage) allows servers to request that the host perform model inference on their behalf, the server has no channel to independently trigger arbitrary host actions. This unidirectional constraint is what makes MCP servers safe to run as untrusted third-party processes: a server cannot independently initiate actions against the host or against other connected services.
<Callout type="warning"> The unidirectional constraint has teeth. If you design an MCP server that tries to call back into the host (e.g., to trigger another tool call), you have broken the security model. The server has no channel for this — and any workaround (e.g., embedding a callback URL in a tool result) should be treated as a red flag in code review. See course/mcp-from-first-principles-to-production/02-json-rpc-over-stdio for how the JSON-RPC framing enforces this at the wire level. </Callout>
What MCP deliberately does NOT solve MCP is a narrow protocol for context injection. Problems it excludes are deferred to higher layers.
- Agent orchestration: No flow control or branching logic. Orchestration (ReAct, plan-and-execute) belongs to the Host.
- Multi-agent coordination: Agents cannot coordinate through MCP. They need separate channels.
- Session persistence: State is gone when the process exits. Persistence is the Host's responsibility.
- Model routing: Model selection and inference parameters are entirely outside MCP.
- Billing and rate limiting: Raw MCP servers are stateless and unauthenticated. These belong to the Gateway/Infrastructure layer (Chapter 5).
The deliberate narrowness is the design. A protocol solving everything would be too complex to be compatible.
I'm building an AI coding assistant that needs to: (1) read files from a GitHub repo, (2) run tests in CI and get results, (3) remember which files the user worked on across sessions, (4) decide wheth…
Show expected output
1. Read files from GitHub repo → MCP's job. A GitHub MCP server with a read_file Resource or Tool handles this directly. 2. Run tests in CI and get results → MCP's job. A CI MCP server with a run_tests Tool handles this. The Tool returns structured results the model can reason over. 3. Remember which files the user worked on across sessions → NOT MCP's job — the host's responsibility. MCP servers are stateless between sessions. Persistent memory belongs to your application layer: a database, vector store, or session management system the host controls. 4. Decide whether to call GitHub or CI first → NOT MCP's job — orchestration. The model (guided by your system prompt and tool descriptions) decides call order. MCP just executes whichever call the model makes. Deterministic ordering is enforced by your host's orchestration logic. 5. Limit CI calls per user per hour → NOT MCP's job — the gateway/infrastructure layer. A raw MCP server has no concept of users or rate limits. You need an MCP gateway (Chapter 5) with RBAC and rate-limiting policies, or a reverse proxy that enforces quotas before requests reach the server.
A minimal MCP server: hello world in ~38 lines
The best way to make the architecture concrete is to read a complete, working MCP server. The following Python implementation is stripped to the minimum that satisfies the MCP specification's initialize handshake and handles a single tool call over stdio.[1]
```python #!/usr/bin/env python3 """Minimal MCP server: exposes one tool (echo) over stdio transport.""" import json import sys
def send(msg: dict) -> None: # Never use print() here — it writes to stdout and corrupts the stdio channel sys.stdout.write(json.dumps(msg) + "\n") sys.stdout.flush()
def handle(msg: dict) -> None: method = msg.get("method") id_ = msg.get("id")
if method == "initialize": send({ "jsonrpc": "2.0", "id": id_, "result": { "protocolVersion": "2024-11-05", "capabilities": {"tools": {}}, "serverInfo": {"name": "hello-mcp", "version": "0.1.0"} } })
elif method == "tools/list": send({ "jsonrpc": "2.0", "id": id_, "result": {"tools": [{ "name": "echo", "description": "Returns the input string unchanged.", "inputSchema": { "type": "object", "properties": {"message": {"type": "string"}}, "required": ["message"] } }]} })
elif method == "tools/call": args = msg.get("params", {}).get("arguments", {}) send({ "jsonrpc": "2.0", "id": id_, "result": {"content": [{"type": "text", "text": args.get("message", "")}]} })
elif method == "notifications/initialized": pass # Notifications receive no response
else: # JSON-RPC 2.0 §5: requests carrying an id MUST receive a response; # only notifications (no id field) may be silently dropped. if id_ is not None: send({ "jsonrpc": "2.0", "id": id_, "error": {"code": -32601, "message": "Method not found"} })
for line in sys.stdin: line = line.strip() if line: handle(json.loads(line)) ```
Run it and drive it manually to see the full lifecycle:
python3 hello_mcp.py << 'EOF'
{"jsonrpc":"2.0","id":1,"method":"initialize","params":{"protocolVersion":"2024-11-05","capabilities":{},"clientInfo":{"name":"test-client","version":"0.1"}}}
{"jsonrpc":"2.0","method":"notifications/initialized"}
{"jsonrpc":"2.0","id":2,"method":"tools/list","params":{}}
{"jsonrpc":"2.0","id":3,"method":"tools/call","params":{"name":"echo","arguments":{"message":"hello, MCP"}}}
EOF
Expected output:
{"jsonrpc": "2.0", "id": 1, "result": {"protocolVersion": "2024-11-05", "capabilities": {"tools": {}}, "serverInfo": {"name": "hello-mcp", "version": "0.1.0"}}}
{"jsonrpc": "2.0", "id": 2, "result": {"tools": [{"name": "echo", "description": "Returns the input string unchanged.", "inputSchema": {"type": "object", "properties": {"message": {"type": "string"}}, "required": ["message"]}}]}}
{"jsonrpc": "2.0", "id": 3, "result": {"content": [{"type": "text", "text": "hello, MCP"}]}}
Every field maps directly to a section of the MCP specification.[1] The protocolVersion in the initialize response is the spec version the server implements — clients use this to decide whether to proceed or reject the connection. The capabilities object is the negotiation surface: if your server doesn't include {"resources": {}} in capabilities, the client will not attempt resources/list. The content array in a tool response is typed — each item has a type field (text, image, resource) that tells the host how to render the result.
Notice what is not in this server: no authentication, no rate limiting, no session management, no orchestration. Those are host and gateway concerns. This server's only job is to expose the echo tool correctly.
I have the minimal echo MCP server from this chapter. Extend it to add a second tool called 'reverse' that takes a 'text' string parameter and returns the string reversed. Show: (1) the updated tools/…
Show expected output
(1) Updated tools/list result body:
{
\<Callout type="hot"> Why stdio, not HTTP, for local servers? This server reads from stdin and writes to stdout — there is no network socket. That means: zero firewall configuration, zero network authentication surface, trivial restart (kill and respawn the process), and clean process isolation (the server dies when its parent dies). The stdio transport is not a dev-environment shortcut. It is the production transport for any MCP server that runs on the same machine as the host. Chapter 2 covers when to switch to HTTP+SSE (Streamable HTTP) for remote servers — and what you give up when you do. </Callout>
Knowledge checks
Hands-on exercise: map your own integrations
Pick three integrations you maintain (APIs, databases, SDKs). For each, answer:
1. Assignment: If this were an MCP server, what's its name? What does the Host own?
2. Primitive: Is it a Tool, Resource, or Prompt?
3. Out-of-scope: Identify one concern MCP leaves to your application (auth, rate limiting, etc.) and explain why.
Structure your answer: "This is an MCP [Tool/Resource/Prompt] exposed by a server named [X]. The host is [Y]. MCP handles [responsibility]. The [auth/rate-limit/etc.] concern belongs to [layer/component] because [reason]."
What's next
Chapter 2 covers the how. In course/mcp-from-first-principles-to-production/02-json-rpc-over-stdio, you will dissect the JSON-RPC 2.0 envelope, implement the initialize lifecycle by hand, and build a 60-line Python server. You'll also learn the trade-offs between stdio and Streamable HTTP (HTTP+SSE).
For roadmap context, blog · mcp-2026-roadmap-explained details the OAuth 2.1 + DPoP trajectory and gateway discovery.
References
[1]: Model Context Protocol Specification — https://modelcontextprotocol.io/specification/ · retrieved 2026-04-30 [2]: MCP 2026 Roadmap (Official Blog) — https://blog.modelcontextprotocol.io/posts/2026-mcp-roadmap/ · retrieved 2026-04-30 [3]: Language Server Protocol Specification 3.17 — https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/ · retrieved 2026-04-30 [4]: JSON-RPC 2.0 Specification — https://www.jsonrpc.org/specification · retrieved 2026-04-30 [5]: MCP Specification GitHub Issues — https://github.com/modelcontextprotocol/specification/issues · retrieved 2026-04-30
References
JSON-RPC over stdio — the wire protocol explained
> Prerequisites: Chapter 1 (Why MCP exists). You should be able to sketch the host/client/server triad and articulate the N×M problem MCP solves. > > Time: 45 minutes > > What you'll be able to do: By the end of this chapter, you can read a raw MCP message exchange at the byte level, explain every design choice in the wire format, and write a working MCP server from scratch without an SDK. This hands-on fluency is what separates developers who can ship MCP integrations from developers who can merely configure them.
Why the wire format matters
Every MCP SDK — the Python mcp package, the TypeScript @modelcontextprotocol/sdk, the Rust crate — is an abstraction layer over the same wire protocol. When something goes wrong in production, the abstraction disappears and you're reading raw JSON in a log file or a debugger. If you don't know what that JSON should look like, you can't diagnose the problem.
- All MCP SDKs abstract over the same underlying wire protocol, so production debugging always reduces to reading raw JSON-RPC messages regardless of which SDK you used.
- Understanding the wire format lets you reason about round-trip costs, structured error shapes, and what attacker-visible information is present in each request.
- SDK fluency without wire fluency means you can configure MCP integrations but cannot diagnose failures when they occur in production.
More importantly: once you understand the wire format, the SDK stops being magic. Every SDK call maps to one or two JSON messages. Once you can see those messages, you can reason about performance (how many round-trips does a tool call require?), error handling (what does a structured error look like vs. a malformed request?), and security (what information is in the request that an attacker could exploit?).
This chapter builds that fluency from scratch.
JSON-RPC 2.0: the message envelope
MCP uses [[JSON-RPC 2.0]][1] as its message format. This is not an implementation detail — it's a deliberate choice with specific consequences. Let's understand it before we look at MCP-specific message types.
- The `id` field in a JSON-RPC request is the correlation mechanism: it allows multiple requests to be in-flight simultaneously because each response carries back the same `id` as its request.
- Notifications are distinguished from requests by the absence of an `id` field; the sender never expects a response, making them the mechanism for unsolicited server-to-client push events.
- The `error` and `result` fields in a response are mutually exclusive — a valid JSON-RPC response carries exactly one of them, never both.
JSON-RPC 2.0 defines four message shapes:
Request (client → server, or server → client)
{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/call",
"params": {
"name": "search_github",
"arguments": { "query": "MCP protocol", "limit": 10 }
}
}
The id field is critical: it's how the response is correlated back to this specific request. In a world where multiple requests can be in-flight simultaneously (the client doesn't wait for one response before sending the next), the id lets both sides match requests to their responses. The id can be a number or a string; MCP conventionally uses integers.
Response (server → client, or client → server)
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"content": [
{ "type": "text", "text": "Found 47 results for 'MCP protocol'" }
],
"isError": false
}
}
Or on error:
{
"jsonrpc": "2.0",
"id": 1,
"error": {
"code": -32602,
"message": "Invalid params",
"data": { "field": "limit", "issue": "must be between 1 and 100" }
}
}
The error and result fields are mutually exclusive. A valid JSON-RPC response has exactly one of them.
Notification (either direction, no response expected)
{
"jsonrpc": "2.0",
"method": "notifications/tools/list_changed",
"params": {}
}
Notice: no `id` field. A notification is a one-way message. The sender never expects a response. This is how MCP servers push events to clients (tool list changes, resource updates, progress on long-running operations) without the client polling.
Batch (array of requests/notifications)
[
{ "jsonrpc": "2.0", "id": 1, "method": "tools/list", "params": {} },
{ "jsonrpc": "2.0", "method": "notifications/initialized", "params": {} }
]
MCP supports batch messages but rarely uses them in practice. Most SDK implementations send messages individually.
The stdio transport: why a pipe beats a socket
The technical choice
For local MCP servers — servers running on the same machine as the host — the MCP spec defines [[MCP stdio transport|stdio transport]]: the host launches the server as a subprocess and communicates via stdin (host → server) and stdout (server → host). Each message is a JSON object terminated by a single newline character (\n).[2]
- Stdio transport uses newline-delimited JSON: the framing rule is read until `\n`, parse as JSON — no sockets, no ports, no TLS configuration required for local servers.
- The subprocess lifecycle model means the server dies automatically when its parent closes the pipe, eliminating the need for explicit cleanup logic that long-running network servers require.
- Stderr is strictly reserved for logs; any log output written to stdout will corrupt the JSON-RPC stream and cause parse errors in the client — the most common first-time MCP implementation mistake.
This is newline-delimited JSON, also called NDJSON or JSON Lines. The framing rule is brutally simple: read until \n, parse what you got as JSON, process it.
``` [host writes to server stdin] {"jsonrpc":"2.0","id":1,"method":"initialize","params":{"protocolVersion":"2025-03-26","capabilities":{},"clientInfo":{"name":"claude-desktop","version":"1.0"}}}\n
[server writes to host stdout] {"jsonrpc":"2.0","id":1,"result":{"protocolVersion":"2025-03-26","capabilities":{"tools":{},"resources":{}},"serverInfo":{"name":"github-mcp","version":"0.1.0"}}}\n
[host writes to server stdin — client signals readiness, no response expected] {"jsonrpc":"2.0","method":"notifications/initialized","params":{}}\n ```
Why not WebSockets?
WebSockets provide a persistent bidirectional connection — sounds like an obvious choice. Here's what you'd actually be choosing:
- Network stack dependency: WebSocket connections require a port, a network interface, and TLS for anything beyond localhost. Running a local MCP server on WebSockets means opening a port on the host machine, managing its lifecycle, ensuring it's not accessible from outside. This is solvable but it's operational overhead that stdio avoids entirely.
- Complex lifecycle management: A WebSocket server is a long-running process. The host needs to know where it's listening (port, hostname), how to restart it if it crashes, and how to clean up when the host exits. With stdio, the lifecycle is implicit: the host forks a subprocess, and the subprocess dies when the host closes its end of the pipe. No cleanup logic required.
- Session multiplexing complexity: WebSocket servers often need to handle multiple concurrent connections. Stdio is inherently single-connection-per-process. For MCP's use case (one client per server connection), this simplicity is a feature.
Why not gRPC?
gRPC is mature, fast, and has excellent schema tooling via Protocol Buffers. The failure modes:
- Protobuf schema requirement: gRPC requires a
.protoschema definition. Every new tool or resource change requires a schema update and re-compilation. MCP's JSON Schema approach allows runtime schema changes (a server can add new tools without recompiling anything). - Binary format opacity: A gRPC message is not human-readable. Debugging a local MCP server by reading its stdio output is trivial with JSON. With Protobuf, you need a decoder.
- Tooling weight: gRPC requires a code generation step, language-specific runtimes, and for web/browser environments, special proxies (grpc-web). JSON-RPC needs only a JSON parser.
Why not REST?
REST over HTTP is request-response only. MCP needs bidirectionality: the server must be able to send unsolicited notifications to the client (tool list changes, resource updates, progress events). With REST, you'd need polling (inefficient, adds latency) or webhooks (requires the client to expose an HTTP server, which is complex for desktop apps). JSON-RPC over stdio gets bidirectionality for free: either side can write to its output at any time.
The initialize handshake: step by step
Every MCP session begins with a three-message handshake[4]. Understanding it prevents a surprising class of bugs where a server works in isolation but fails when connected to a real host.
- The three-message handshake (initialize request → initialize response → notifications/initialized) must complete before any tool calls are valid; requests sent before `notifications/initialized` are a protocol violation.
- Each side's `capabilities` object is the negotiation surface: if a server omits `{"resources": {}}` from its capabilities, the client will not attempt `resources/list` — the handshake determines the entire call surface.
- The client sends `notifications/initialized` as a notification (no `id`) to signal readiness; the server does not respond to it, and the session becomes live immediately after.
Message 1: initialize (client → server)
{
"jsonrpc": "2.0",
"id": 0,
"method": "initialize",
"params": {
"protocolVersion": "2025-03-26",
"capabilities": {
"roots": { "listChanged": true },
"sampling": {}
},
"clientInfo": {
"name": "claude-desktop",
"version": "1.2.0"
}
}
}
The client declares:
- protocolVersion — the version it wants to speak. Servers should accept any version they support; the spec doesn't mandate that servers reject older versions.
- capabilities — what the client can do. roots.listChanged means the client supports notifications when the root (workspace) changes. sampling means the client supports the server requesting LLM completions via the host.
- clientInfo — for logging and diagnostics.
Message 2: initialize response (server → client)
{
"jsonrpc": "2.0",
"id": 0,
"result": {
"protocolVersion": "2025-03-26",
"capabilities": {
"tools": { "listChanged": true },
"resources": { "subscribe": true, "listChanged": true },
"prompts": { "listChanged": true },
"logging": {}
},
"serverInfo": {
"name": "github-mcp",
"version": "0.2.1"
}
}
}
The server declares its capabilities:
- tools.listChanged — the server will send notifications/tools/list_changed when its tool set changes.
- resources.subscribe — clients can subscribe to resource updates.
- logging — the server supports the logging/setLevel request.
Capabilities not declared here are not supported. If the client tries to use an undeclared capability, the server may return an error or silently ignore the request.
Message 3: notifications/initialized (client → server, notification)
{
"jsonrpc": "2.0",
"method": "notifications/initialized",
"params": {}
}
This is the client saying "I've processed your initialize response and I'm ready." No id, no response expected. After this, the session is live and the client can send any supported request.
The entire handshake is synchronous: no other messages can be sent until notifications/initialized is dispatched. This is important for implementations that try to pre-load tool lists before the handshake completes — they'll get a protocol error.
A client has just received the server's initialize response containing the server's capabilities. What is the NEXT message the client MUST send, and why? What happens if it skips this step and sends t…
Show expected output
The client must send 'notifications/initialized' — a JSON-RPC notification (no id) with method='notifications/initialized' and empty params. This signals to the server that the client has processed the initialize response and the session is live. If the client skips this and sends tools/list directly, it violates the MCP handshake protocol. Spec-compliant servers should treat any non-handshake request before notifications/initialized as a protocol error, potentially returning -32600 (Invalid Request) or closing the connection.
Reading a real MCP exchange
Let's trace a complete tool call from wire to result. The scenario: a user in Claude Desktop asks "What are my open GitHub PRs?" and the host invokes the list_pull_requests tool on a GitHub MCP server.
Step 1: Host discovers available tools.
```json → {"jsonrpc":"2.0","id":2,"method":"tools/list","params":{}}
← { "jsonrpc":"2.0", "id":2, "result":{ "tools":[ { "name":"list_pull_requests", "description":"List open pull requests for a repository", "inputSchema":{ "type":"object", "properties":{ "owner":{"type":"string","description":"GitHub org or username"}, "repo":{"type":"string","description":"Repository name"}, "state":{"type":"string","enum":["open","closed","all"],"default":"open"} }, "required":["owner","repo"] } } ] } } ```
The inputSchema is a JSON Schema object[3]. This is what the host passes to the model to describe the tool's calling convention. The model uses this schema to decide what arguments to generate.
Step 2: Model decides to call the tool. Host sends tools/call.
→ {
"jsonrpc":"2.0",
"id":3,
"method":"tools/call",
"params":{
"name":"list_pull_requests",
"arguments":{
"owner":"anthropics",
"repo":"anthropic-sdk-python",
"state":"open"
}
}
}
Step 3: Server calls the GitHub API, returns the result.
← {
"jsonrpc":"2.0",
"id":3,
"result":{
"content":[
{
"type":"text",
"text":"Found 12 open PRs:\n1. #847 — Add streaming support for tool_use...\n2. #821 — Fix retry logic on 529..."
}
],
"isError":false
}
}
Step 4: If the tool failed (GitHub API down, bad credentials):
← {
"jsonrpc":"2.0",
"id":3,
"result":{
"content":[
{
"type":"text",
"text":"GitHub API returned 401: Bad credentials. Check your GITHUB_TOKEN environment variable."
}
],
"isError":true
}
}
Note: tool errors use isError: true in the result, NOT the JSON-RPC error field. The JSON-RPC error field is reserved for protocol errors (malformed request, unknown method). Separating protocol errors from tool errors is a deliberate design choice: a protocol error means the server couldn't understand the request; a tool error means the server understood the request but execution failed. The host handles these differently.
I'm reading MCP server logs and I see this message arrive on stdin: {\
Show expected output
The expert covers: (1) validate jsonrpc='2.0', id exists, method='tools/call', params.name matches a known tool, params.arguments validates against the tool's inputSchema — if any fail, return a JSON-RPC error with code -32602. (2) result.content array with text content and isError:false. (3) result.content with the error message and isError:true — NOT a JSON-RPC error object, because the protocol worked fine; only the tool execution failed.
HTTP Streaming transport: when stdio isn't enough
Stdio is perfect for local servers. But you can't run a stdio process when the MCP server is a cloud API — when the server is a SaaS vendor's integration, a company-wide shared endpoint, or a multi-tenant service.
The MCP spec defines an HTTP Streaming transport (formerly called HTTP+SSE; the 2025 spec revision renamed and updated it)[2] for remote servers. The key differences:
Connection model: Instead of a subprocess pipe, the client makes HTTP POST requests to a single endpoint. The server can respond with a streaming body (using chunked transfer encoding) to push multiple messages in one HTTP response.
Message format: Same JSON-RPC 2.0 envelope. Same newline delimiting. The wire format is identical; only the carrier changes.
Bidirectionality: Because HTTP is inherently request-initiated, server-to-client notifications can't be sent spontaneously. The spec handles this with Server-Sent Events (SSE) on a separate /events endpoint, or in the updated Streamable HTTP transport, by allowing the server to include multiple JSON-RPC messages in a single streaming response body.
Session management: HTTP is stateless. The client includes a session identifier in each request header so the server can correlate requests to the same logical session.
Auth: HTTP headers carry auth credentials (Bearer tokens, DPoP proofs — covered in Chapter 4). Stdio has no native auth mechanism; security relies on process-level isolation instead.
The choice between transports is architectural:
| Scenario | Transport |
|---|---|
| Local tool running on developer's machine | stdio |
| Internal service running in Kubernetes | HTTP Streaming |
| SaaS vendor's integration endpoint | HTTP Streaming |
| CI/CD pipeline action | stdio (subprocess) |
| Multi-tenant shared MCP server | HTTP Streaming |
| Desktop IDE plugin | stdio |
A team is building a SaaS vendor integration that will serve thousands of tenants, each making concurrent MCP requests. Which MCP transport should they choose, and what are the three main protocol dif…
Show expected output
The team should choose HTTP Streaming transport. Three key differences vs stdio: (1) Session management — HTTP is stateless, so each request must include a session identifier in request headers so the server can correlate requests to the same logical session; (2) Server-push mechanism — stdio lets the server write to stdout at any time, but HTTP requires Server-Sent Events (SSE) on a /events endpoint or a streaming response body for server-to-client notifications; (3) Authentication — HTTP headers carry Bearer tokens or DPoP proofs for per-request auth, while stdio relies on OS process isolation with no native auth mechanism.
Hands-on exercise: a 60-line MCP server, no SDK
This is the most important exercise in the course. You're going to write an MCP server from scratch, in Python, using only sys.stdin and sys.stdout. No mcp package. This forces you to confront every design decision we've discussed.
What the server will do: Handle tools/list (returns one tool: echo) and tools/call for the echo tool (returns whatever string argument was passed). This is the low-level equivalent of the patterns you'll find in the official Python SDK[5], implemented without any abstraction so every design choice is visible.
Complete implementation:
```python #!/usr/bin/env python3 """ Minimal MCP server over stdio. No SDK. Raw JSON-RPC 2.0. Run: python server.py Test: echo '{"jsonrpc":"2.0","id":0,"method":"initialize","params":{"protocolVersion":"2025-03-26","capabilities":{},"clientInfo":{"name":"test","version":"1.0"}}}' | python server.py """ import sys import json
PROTOCOL_VERSION = "2025-03-26"
TOOLS = [ { "name": "echo", "description": "Returns the input string unchanged. Useful for testing.", "inputSchema": { "type": "object", "properties": { "message": {"type": "string", "description": "Text to echo back"} }, "required": ["message"] } } ]
def send(obj: dict) -> None: """Write a JSON-RPC message to stdout. stderr only for logs.""" line = json.dumps(obj, separators=(",", ":")) sys.stdout.write(line + "\n") sys.stdout.flush()
def error_response(req_id, code: int, message: str) -> dict: return {"jsonrpc": "2.0", "id": req_id, "error": {"code": code, "message": message}}
def handle(msg: dict) -> None: method = msg.get("method") req_id = msg.get("id") # None for notifications params = msg.get("params", {})
if method == "initialize": send({ "jsonrpc": "2.0", "id": req_id, "result": { "protocolVersion": PROTOCOL_VERSION, "capabilities": {"tools": {}}, "serverInfo": {"name": "echo-server", "version": "0.1.0"} } }) # The server stops here. The CLIENT then sends notifications/initialized # to signal readiness — never the other way around.
elif method == "tools/list": send({"jsonrpc": "2.0", "id": req_id, "result": {"tools": TOOLS}})
elif method == "tools/call": tool_name = params.get("name") args = params.get("arguments", {}) if tool_name == "echo": message = args.get("message", "") send({ "jsonrpc": "2.0", "id": req_id, "result": {"content": [{"type": "text", "text": message}], "isError": False} }) else: send(error_response(req_id, -32601, f"Unknown tool: {tool_name}"))
elif req_id is not None: # Unknown method with an id: return method-not-found error send(error_response(req_id, -32601, f"Method not found: {method}")) # Unknown notifications are silently ignored (no id, no response expected)
def main(): print("echo-server starting", file=sys.stderr) for line in sys.stdin: line = line.strip() if not line: continue try: msg = json.loads(line) except json.JSONDecodeError as e: send(error_response(None, -32700, f"Parse error: {e}")) continue handle(msg)
if __name__ == "__main__": main() ```
Testing it from the terminal (sequence matters — you need the initialize handshake first):
# Save as echo_server.py, then:
python3 echo_server.py << 'EOF'
{"jsonrpc":"2.0","id":0,"method":"initialize","params":{"protocolVersion":"2025-03-26","capabilities":{},"clientInfo":{"name":"test","version":"1.0"}}}
{"jsonrpc":"2.0","method":"notifications/initialized","params":{}}
{"jsonrpc":"2.0","id":1,"method":"tools/list","params":{}}
{"jsonrpc":"2.0","id":2,"method":"tools/call","params":{"name":"echo","arguments":{"message":"hello MCP"}}}
EOF
Expected output (one JSON object per line on stdout):
{"jsonrpc":"2.0","id":0,"result":{"protocolVersion":"2025-03-26","capabilities":{"tools":{}},"serverInfo":{"name":"echo-server","version":"0.1.0"}}}
{"jsonrpc":"2.0","id":1,"result":{"tools":[{"name":"echo","description":"Returns the input string unchanged. Useful for testing.","inputSchema":{"type":"object","properties":{"message":{"type":"string","description":"Text to echo back"}},"required":["message"]}}]}}
{"jsonrpc":"2.0","id":2,"result":{"content":[{"type":"text","text":"hello MCP"}],"isError":false}}
What to verify:
- Every response has the same id as its corresponding request
- The client's notifications/initialized (line 2 of the input) produces no server output — it's a notification with no id, so the server correctly produces no response
- stderr shows "echo-server starting" (logs stay off stdout)
- A call to an unknown tool returns a JSON-RPC error object, not isError:true in result
Estimated time: 20 minutes to type/copy, run, and understand the output.
Review this Python MCP server implementation and identify three specific improvements that would make it production-ready. Focus on: error handling edge cases, logging, and correctness of the JSON-RPC…
Show expected output
The reviewer identifies: (1) No handling for stdin closing (EOF) — the for loop exits silently when stdin closes; a production server should log the shutdown and call sys.exit(0) for clean process termination. (2) No validation that the 'jsonrpc' field equals '2.0' — a malformed client could send a JSON object that passes json.loads but is not a valid JSON-RPC envelope, and the server would attempt to process it. (3) No handshake state machine — the server accepts tools/call or tools/list before the initialize handshake completes, violating the MCP spec's sequencing requirement; a robust implementation should track whether notifications/initialized has been received and return -32600 for premature requests.
Error codes reference
JSON-RPC 2.0 defines standard error codes[1] that MCP uses for protocol-level errors:
| Code | Name | When to use |
|---|---|---|
| -32700 | Parse error | Invalid JSON received |
| -32600 | Invalid Request | Valid JSON but not a valid JSON-RPC message |
| -32601 | Method not found | Unknown method name |
| -32602 | Invalid params | Method exists but params are wrong type/missing required |
| -32603 | Internal error | Server-side bug during processing |
MCP-specific error codes start at -32000 and go down. Application-specific errors (your tool's domain errors) go in result.isError:true, not in the error field.
What's next
In Chapter 3, we zoom out from the wire protocol to the three semantic primitives: Tools, Resources, and Prompts. You now understand how any MCP message travels from client to server and back. Chapter 3 teaches you what to put in those messages — specifically, which primitive is the right abstraction for any given integration requirement. This is where most developers make wrong choices that are expensive to fix later.
References cited
[1]: JSON-RPC 2.0 Specification — Defines the message envelope format, error codes, notification semantics, and batch requests that MCP uses verbatim.
[2]: MCP Transports Specification — Defines stdio transport (newline-delimited JSON over subprocess pipes) and HTTP Streaming transport for remote servers.
[3]: JSON Schema Specification — The inputSchema field in MCP tool definitions is a JSON Schema object. Familiarity with draft 2020-12 is useful for writing precise tool definitions.
[4]: MCP Core Specification (2025-03-26) — The authoritative specification for the Model Context Protocol, covering the full message lifecycle, capability negotiation, and the initialize handshake sequencing requirements. URLs verified 200 OK as of 2026-04-30.
[5]: MCP Python SDK — The official Python SDK for MCP servers and clients; the mcp package this chapter intentionally avoids to make the raw wire protocol visible.
- MCP 2026 Roadmap — Transport Evolution — The roadmap priority on HTTP streaming and
.well-knownmetadata directly affects how remote MCP servers are discovered and connected.
References
Tools, Resources, Prompts — the three primitives and the decision rule
Tools, Resources, and Prompts are the three primitive types defined by the Model Context Protocol (MCP), introduced by Anthropic in 2024. Each primitive represents a distinct pattern for how language model hosts, clients, and servers expose and consume capabilities: Tools for model-initiated operations that may have side effects, Resources for read-only data identified by URI, and Prompts for structured reusable message templates. Choosing the correct primitive for a given integration requirement is the primary design decision in MCP server development; conflating them is the most common source of correctness and performance problems.
Key facts
- MCP defines exactly three primitive types — Tools, Resources, and Prompts — each with a distinct initiation model, side-effect posture, and wire protocol.
- Tools are model-initiated operations that may have side effects; declared via
tools/listand invoked viatools/call, with aninputSchema(JSON Schema) describing arguments. - Resources are read-only data objects identified by URIs or RFC 6570 URI templates; listed via
resources/listand fetched viaresources/read; can support live subscriptions. - Prompts are user-selected reusable message templates with named arguments; listed via
prompts/listand rendered to a message sequence viaprompts/get. - The "who initiates / who controls / what mutates" decision rule provides a three-question test that correctly classifies any integration requirement into one of the three primitives.
- Conflating Tools and Resources is the most common MCP design mistake: using a zero-argument Tool where a Resource belongs wastes token budget on unnecessary tool-call round-trips and removes the host's ability to pre-load context.
> Prerequisites: Chapter 1 (the N×M problem and host/client/server triad) and Chapter 2 (the wire protocol). You should have the echo-server from Chapter 2 working. > > Time: 40 minutes > > What you'll be able to do: By the end of this chapter, you can classify any integration requirement as Tool, Resource, or Prompt without hesitation, understand the protocol messages for each, and implement the Resources primitive with URI templating. This decision fluency is what separates an MCP server that's easy to maintain from one that gradually becomes an incoherent mess.
The mistake almost every developer makes
Ask a developer to build an MCP server for their internal knowledge base. Nine out of ten will build a Tool called search_docs that takes a query string and returns matching documents. Fast to write. Reasonable API. Completely wrong primitive.
- Using a Tool for read-only data that the host could pre-load wastes an LLM inference turn and a server round-trip on every access, when a Resource would let the host inject the content before the model even asks.
- The host can proactively surface Resources before the conversation starts; it cannot do the same for Tools — only the model initiates Tool calls.
- Choosing the wrong primitive is not easily refactored once clients depend on it, because it changes the initiation model and the wire protocol used to access the data.
The knowledge base is read-only data the model should be able to access, not a query the model should execute. The correct primitive is a Resource — possibly many Resources, one per document, with a URI scheme like docs://handbook/engineering/onboarding. The model reads resources; the host decides which resources to surface. Conflating these means you're burning tokens on tool invocations when you could be injecting context directly, and you're losing the host's ability to pre-load commonly-needed documents before the model even asks.
Understanding the three primitives at the level of their design intent — not just their API shape — is the difference between an MCP server that works and one that works well.
Tools — what the model executes
One-sentence definition: A Tool is an operation the model initiates that may have side effects and returns a result.
- Tools are the only MCP primitive where mutation is expected — creating, deleting, or triggering side effects are all Tool-exclusive operations.
- The `description` field in `inputSchema` is a prompt that the model reads to decide when and how to call the tool; vague descriptions produce vague or incorrect tool calls.
- Any user who can talk to the model can potentially trigger any Tool in the server's list — tool description text is not a security boundary.
The keyword is may have side effects. Tools are the only MCP primitive where mutation is expected and permitted. Creating a Jira ticket, running a SQL query, sending a Slack message, executing a shell command — all of these are Tools because they change something outside the conversation.
Wire format
Tools are declared via tools/list and invoked via tools/call. You've seen both in Chapter 2. The critical field is inputSchema — a JSON Schema object that the host passes to the model to describe what arguments the tool accepts.[1]
A well-designed inputSchema is worth spending time on. It directly shapes the quality of model-generated tool calls:
{
"name": "create_github_issue",
"description": "Create a new issue in a GitHub repository. Use when the user explicitly asks to create or file a bug report or feature request.",
"inputSchema": {
"type": "object",
"properties": {
"owner": {
"type": "string",
"description": "GitHub org or username that owns the repository"
},
"repo": {
"type": "string",
"description": "Repository name (without the owner prefix)"
},
"title": {
"type": "string",
"description": "Issue title. Should be concise and descriptive (under 80 characters)."
},
"body": {
"type": "string",
"description": "Issue body in GitHub-flavored Markdown. Include: description, steps to reproduce (if bug), expected vs actual behavior."
},
"labels": {
"type": "array",
"items": { "type": "string" },
"description": "Label names to apply. Must match existing labels in the repo.",
"default": []
}
},
"required": ["owner", "repo", "title"]
}
}
Here is a poorly-written `inputSchema` for a `send_slack_message` tool. Identify 3 specific problems and rewrite it.\n\n```json\n{\n \
Show expected output
A good answer identifies: (1) Description is too vague — 'Send a message' gives the model no signal about when to call it, which platform, or how channel should be formatted (Slack channel ID like C01234567 vs display name). (2) No required fields — both channel and message should be required; the model could omit them and produce an invalid call. (3) No property descriptions — the model doesn't know the channel must be a Slack channel ID, or that message supports Slack markdown, or that urgent defaults to false. The rewrite should add a useful tool description with a usage trigger, mark channel/message as required, add property descriptions with format hints, and add a default of false for urgent.
Three principles for good tool schemas:
1. The `description` field is a prompt. The model reads it to decide when and how to call the tool. Vague descriptions produce vague calls.
2. Required vs optional matters. Put the minimum viable set in required. Optional fields with sensible defaults make the model's job easier.
3. Enum constraints reduce hallucination. If a field has a fixed set of valid values, use "enum": [...]. The model is more likely to pass valid values when it knows the allowed set.
Control flow: model-initiated
This is the distinguishing property. The model decides when to call a tool, whether to call it at all, and what arguments to pass. The host can show the model a list of available tools and can execute tool calls on the model's behalf, but it cannot force the model to use a specific tool or prevent the model from calling a tool it's already seen.
This means Tools have a different security posture than Resources: any user who can talk to the model can potentially trigger any Tool in the server's list. Chapter 4 covers how OAuth scopes and gateway RBAC address this.
Resources — what the model reads
One-sentence definition: A Resource is read-only data identified by a URI that either the model or the application can inject into context.
- Resources differ from Tools in initiation: the host application can proactively inject Resource content before the conversation starts, without any model inference turn.
- Resource templates use RFC 6570 URI template syntax with variable placeholders (e.g. `github://{owner}/{repo}/blob/{branch}/{path}`), allowing a single template to represent an unbounded set of concrete resources without enumeration.
- The pull-on-push subscription pattern means the server sends `notifications/resources/updated` when content changes, but never pushes large payloads — the client re-reads the resource on its own.
The "either the model or the application" part is why Resources exist as a separate primitive. With Tools, only the model initiates. With Resources, the host application can also proactively inject resource content into context without the model asking. Claude Desktop can decide to load the contents of file:///Users/alice/project/README.md into context before the conversation starts. The model never had to "call" anything; the host made an editorial decision about what context to provide.
Wire format
Resources are listed via resources/list and read via resources/read.[2] Each resource has a URI and a MIME type:
{
"jsonrpc": "2.0",
"id": 4,
"result": {
"resources": [
{
"uri": "docs://handbook/engineering/onboarding",
"name": "Engineering Onboarding Guide",
"description": "Step-by-step guide for new engineers joining the team",
"mimeType": "text/markdown"
},
{
"uri": "docs://handbook/engineering/incident-response",
"name": "Incident Response Runbook",
"mimeType": "text/markdown"
}
]
}
}
To read a resource:
```json → {"jsonrpc":"2.0","id":5,"method":"resources/read","params":{"uri":"docs://handbook/engineering/onboarding"}}
← { "jsonrpc":"2.0", "id":5, "result":{ "contents":[ { "uri":"docs://handbook/engineering/onboarding", "mimeType":"text/markdown", "text":"# Engineering Onboarding Guide\n\n## Week 1\n..." } ] } } ```
The content can be text (for text/markdown, text/plain, application/json) or blob (base64-encoded binary, for images, PDFs, etc.).[2]
URI templating: the power feature
Static URIs are fine for a fixed set of resources. Real-world resources are dynamic: files in a repo, rows in a database, objects in S3. For these, MCP supports resource templates — URI patterns with variable placeholders:[2]
{
"uriTemplate": "github://{owner}/{repo}/blob/{branch}/{path}",
"name": "GitHub file content",
"description": "Read the content of any file in any GitHub repository at any branch",
"mimeType": "text/plain"
}
The {owner}, {repo}, {branch}, and {path} placeholders follow RFC 6570 URI Template syntax.[4] The host expands the template with actual values (either model-generated or app-provided) and sends the expanded URI in resources/read.
This enables a single resource template to represent billions of concrete resources — every file, in every repo, at every branch — without the server having to enumerate them.
Resource subscriptions
For resources that change (a live config file, a database view, real-time metrics), the server can support subscriptions. The client sends resources/subscribe with a URI; the server sends notifications/resources/updated when the content changes. The client then re-reads the resource.
This is the pull-on-push pattern: notifications tell you something changed; you fetch the new content yourself. The server never pushes large payloads proactively.
I'm building an MCP server for a company's internal documentation system (Confluence-like). The system has: 10,000 pages, 500 spaces, real-time page updates when editors save. Design the Resources sch…
Show expected output
A good answer: (1) URI scheme like docs://{space}/{page-id} or docs://{space}/{page-slug} — page-slug is human-readable but can have conflicts; page-id is stable. (2) Resource templates for individual pages (can't enumerate 10k pages statically), plus static resources for space/index pages. (3) Yes subscriptions — editors saving pages should push updates to clients that have loaded the page into context; otherwise stale content is injected. The answer should also flag that 10k pages is too many for a full static list — pagination via cursor is needed.Prompts — what the user selects
One-sentence definition: A Prompt is a user-initiated, parameterised message template that the host exposes as a selectable option in its UI.
This is the least-understood primitive. Many developers skip Prompts entirely because they look optional — and they're wrong.
The key distinction: Tools are model-initiated; Prompts are user-initiated. The user looks at a menu of available Prompts in their host application, selects one (like selecting a Slash Command), fills in the arguments, and the host renders the Prompt template into a message that kicks off the conversation.
Wire format
Prompts are listed via prompts/list and fetched via prompts/get:[3]
{
"prompts": [
{
"name": "code_review",
"description": "Generate a thorough code review for a pull request",
"arguments": [
{
"name": "pr_url",
"description": "GitHub pull request URL",
"required": true
},
{
"name": "focus",
"description": "What to focus on: security, performance, style, or all",
"required": false
}
]
}
]
}
When the user selects this prompt and provides arguments, the host sends prompts/get:
```json → { "jsonrpc":"2.0","id":6,"method":"prompts/get", "params":{ "name":"code_review", "arguments":{ "pr_url":"https://github.com/anthropics/sdk-python/pull/847", "focus":"security" } } }
← { "jsonrpc":"2.0","id":6, "result":{ "description":"Code review prompt for PR #847", "messages":[ { "role":"user", "content":{ "type":"text", "text":"Please review this pull request with a focus on security vulnerabilities:\n\nhttps://github.com/anthropics/sdk-python/pull/847\n\nFor each issue found:\n1. Describe the vulnerability\n2. Assess the severity (critical/high/medium/low)\n3. Suggest a specific fix\n4. Note any positive security practices you observe" } } ] } } ```
The server returns rendered messages — the actual text that will be injected into the conversation. The Prompt is the template; prompts/get with arguments is the render step.
Design a `prompts/list` response for a customer-support MCP server. Then show the `prompts/get` response for one of those prompts with realistic arguments filled in.
Show expected output
A good answer: prompts/list should have 2-4 prompts such as 'draft_reply' (arguments: ticket_id, tone), 'summarise_ticket' (arguments: ticket_id), 'escalation_template' (arguments: ticket_id, reason). The prompts/get response should show a realistic messages array — the actual rendered text with argument values substituted in — not just a template string. The rendered message should be something a support agent would actually send, with the ticket context embedded.
When Prompts beat system prompts
Prompts have a structural advantage over static system prompt text: they're discoverable, named, and parameterised at runtime. A host application can show users a searchable library of available Prompts across all connected MCP servers. This is the equivalent of Slash Commands in Slack or Linear — a user interface for structured intent.
Use a Prompt when: - The task is user-initiated and repeatable (code review, draft an email, analyse a document) - The task has well-known arguments that vary per invocation - You want the task to appear as a named, discoverable option in the host UI
The decision rule
Every integration requirement can be classified with three questions:
- The three-question test (who initiates / what does it do / who controls access policy) provides a deterministic classification for any integration requirement into Tool, Resource, or Prompt.
- Side effects are a decisive signal: if an operation may write, create, or delete, it is always a Tool — never a Resource or Prompt regardless of the other answers.
- A zero-argument Tool that returns stable per-session data is a Resource in disguise: it wastes inference turns on data the host could pre-load via `resources/read`.
Who initiates? - Model decides autonomously → Tool - User selects from a menu → Prompt - App pre-loads into context (or model requests by URI) → Resource
What does it do? - May write, create, delete, or trigger side effects → Tool (not Resource, never Prompt) - Reads data, produces output → could be Tool or Resource; continue to next question - Provides a structured conversation template → Prompt
Who should control the access policy? - App/platform makes a policy decision about what data is available → Resource - Model decides dynamically based on conversation context → Tool
As a quick-reference table:
| Requirement | Primitive | Why |
|---|---|---|
| Search internal Slack messages | Tool | Model-initiated, returns results on demand |
| Current on-call schedule (read-only, changes daily) | Resource | App can pre-load; model reads by URI; no side effects |
| Create a Jira ticket | Tool | Side effects (creates an object); model-initiated |
| "Draft incident post-mortem" template | Prompt | User-selected; parameterised by incident ID |
| List all employees in HR system | Resource (template) | Read-only data; URI scheme hr://employees |
| Provision a cloud VM | Tool | Irreversible side effect; model-initiated with confirmation |
| Coding style guidelines document | Resource | Static content; app pre-loads into context |
| "Explain this error" workflow | Prompt | User-initiated; arguments: error message, language |
A team wants to add 'get recent alerts from PagerDuty (last 24 hours)' to their MCP server. Apply the three-question decision rule and classify it as Tool, Resource, or Prompt. Justify each answer.
Show expected output
A good answer works through all three questions: (1) Who initiates? — This is ambiguous; could be model-initiated on demand (Tool) or app-pre-loaded (Resource). The 'last 24 hours' filter makes it dynamic. (2) What does it do? — Read-only, no side effects — could be Tool or Resource. (3) Who controls access policy? — The on-call team's tooling (app) decides what alert data is available; the model doesn't need to decide dynamically. Best classification: Resource with a URI like pagerduty://alerts/recent and a subscription for live updates. The model or host can read it by URI. A Tool would be correct only if the query needs dynamic parameters (e.g. arbitrary time ranges the model decides on). The answer should flag the tradeoff between static Resource (simpler, cacheable) and dynamic Tool (flexible query).
Hands-on exercise: classify and implement a GitHub integration
Part 1 — Classification (10 min)
Given this GitHub integration requirements list, classify each as Tool, Resource, or Prompt with one sentence of justification:
- List all open pull requests for a repository
- Read the content of any file at any commit SHA
- Create a new pull request
- Get the authenticated user's GitHub profile (read-only, stable per session)
- Search code across all repos by keyword
- "Write a release announcement" template that takes version number and changelog
- Get the CI/CD status for a specific commit SHA
- Subscribe to PR review notifications
Reference answers:
1. Tool — model-initiated, read-only but dynamic (PRs change constantly); needs to be on-demand
2. Resource — URI template github://{owner}/{repo}/blob/{sha}/{path}, read-only, model or app can load by URI
3. Tool — creates a new object (side effect), model-initiated with arguments
4. Resource — URI github://user/profile, stable per session, host pre-loads
5. Tool — model-initiated search across a dynamic corpus; results change; side-effect-free but dynamic
6. Prompt — user-selected template, arguments: version and changelog text
7. Resource — URI github://{owner}/{repo}/commit/{sha}/status, read-only status object
8. (Trick question) — notification subscriptions are not a primitive; they're a transport feature of Resources that support subscribe. This is a Resource with subscription enabled.
Part 2 — Implement the Resources endpoint (10 min)
Add a resources/list and resources/read handler to the echo server from Chapter 2. Implement the GitHub file resource with URI templating.
```python import re
def handle_resource_read(uri: str, req_id) -> None: m = GITHUB_FILE_RE.match(uri) if not m: send(error_response(req_id, -32602, f"Unsupported resource URI: {uri}")) return owner, repo, branch, path = m.group("owner"), m.group("repo"), m.group("branch"), m.group("path") # In a real server: fetch from GitHub API with auth # For this exercise: return a simulated response content = f"# Simulated content\nowner={owner}, repo={repo}, branch={branch}, path={path}" send({ "jsonrpc": "2.0", "id": req_id, "result": { "contents": [{"uri": uri, "mimeType": "text/plain", "text": content}] } })
Verification: Test with:
``bash
echo '{"jsonrpc":"2.0","id":5,"method":"resources/read","params":{"uri":"github://anthropics/sdk-python/blob/main/README.md"}}' | python3 echo_server.py
``
Confirm you get a valid result.contents response, not an error.
What's next
In Chapter 4, we address the question that security teams ask immediately: "Who is allowed to call these tools?" You've built a server that responds to any client. Chapter 4 wires up OAuth 2.1 with DPoP token binding so your server can verify the identity of callers, reject unauthorized requests with properly structured errors, and emit an audit trail that names who called what.
References cited
[1]: MCP Tools Specification — Defines the tools/list, tools/call protocol, inputSchema (JSON Schema), and the isError vs JSON-RPC error distinction.
[2]: MCP Resources Specification — Defines resources/list, resources/read, resource templates (RFC 6570 URI Templates), subscriptions, and MIME type handling.
[3]: MCP Prompts Specification — Defines prompts/list, prompts/get, argument specification, and the rendered message format.
[4]: RFC 6570 — URI Template (IETF) — Defines the URI template syntax used by MCP resource templates.
- JSON Schema Specification — The schema format used for
inputSchemain tool definitions.
References
- https://spec.modelcontextprotocol.io/specification/2025-03-26/server/tools/
- https://spec.modelcontextprotocol.io/specification/2025-03-26/server/resources/
- https://spec.modelcontextprotocol.io/specification/2025-03-26/server/prompts/
- https://json-schema.org/specification
- https://www.rfc-editor.org/rfc/rfc6570
OAuth 2.1 + DPoP — production auth for MCP servers
OAuth 2.1 and DPoP together solve the production authentication problem for HTTP-based MCP servers: OAuth 2.1 tightens the grant flow (mandatory PKCE, no implicit grant), while DPoP cryptographically binds each access token to the client's private key so that a stolen token is useless without it. This chapter explains both mechanisms, implements DPoP validation on the Chapter 2 echo server, and covers the .well-known/oauth-authorization-server discovery endpoint required by compliant MCP clients.
> Prerequisites: Chapter 1 (architecture overview) and Chapter 2 (wire protocol, the echo server). Chapter 3 is helpful context but not required.
>
> Time: 55 minutes
>
> What you'll be able to do: By the end of this chapter, you can explain exactly what DPoP token binding prevents, implement a server that validates DPoP-bound access tokens on every tool call, and write the .well-known metadata endpoint that makes your server discoverable by compliant MCP clients. You'll also understand why "we're internal-only" is not a justification for skipping this step.
Key facts
- OAuth 2.1 is a consolidation of OAuth 2.0 (RFC 6749) that makes PKCE mandatory for all grants and removes the implicit grant and resource owner password credentials grant entirely.[2]
- DPoP (RFC 9449) adds a proof JWT to every token request and API call that binds the access token to the client's public key — making stolen tokens useless without the matching private key.[3]
- The MCP auth spec requires remote servers to expose a
/.well-known/oauth-authorization-servermetadata document (RFC 8414[4]) that declares supported grant types, token endpoints, and capabilities. - Bearer token theft is a real attack vector in MCP deployments: prompt injection attacks can cause models to leak token values into tool call arguments; log aggregators can inadvertently capture
Authorizationheaders. - SEP-1932 (DPoP) and SEP-1933 (Workload Identity Federation) are listed on the MCP roadmap as "On the Horizon" — community-driven work that maintainers are not yet actively initiating.[1]
- For stdio servers: auth is process-level; the OS enforces that only the parent process can read from the subprocess's stdout. OAuth is only required for HTTP transport.
The authentication problem MCP solved badly at first
The initial MCP specification shipped with a minimal auth story: for stdio servers, security came from process-level isolation (only the host that launched the process can talk to it); for HTTP servers, the spec recommended Bearer tokens but left the specifics up to implementors.
- The initial MCP spec left HTTP server auth unspecified, resulting in real production problems: tokens in log pipelines, tokens exfiltrated via prompt injection, and multi-tenant servers accepting tokens issued for different tenants.
- Two SEPs on the 2026 roadmap address this gap: SEP-1932 (DPoP as mandatory token binding for remote servers) and SEP-1933 (Workload Identity Federation for machine-to-machine access).
- For stdio servers, OAuth is not required — security comes from OS-level process isolation: only the host process that launched the subprocess can communicate with it via the pipe.
That gap creates real problems in HTTP deployments. Production MCP servers encounter Bearer token edge cases that the spec left unaddressed: tokens appearing in structured log pipelines, tokens exfiltrated via prompt injection into tool arguments, and multi-tenant servers accidentally accepting tokens issued for a different tenant because no standard binding validation existed.
The 2026 roadmap lists two SEPs (Specification Enhancement Proposals) to address this[1]: - SEP-1932: DPoP (Demonstration of Proof-of-Possession) as the mandatory binding mechanism for access tokens on remote MCP servers - SEP-1933: Workload Identity Federation for machine-to-machine MCP server access
This chapter covers both the current auth spec[5] and the SEP-1932 design so you're building for where the protocol is going, not where it was.
OAuth 2.1: what changed and why it matters
OAuth 2.0 (2012) was designed for a world of server-rendered web apps and mobile apps with long-lived refresh tokens. Over the years, several of its grant types were found to have exploitable weaknesses. OAuth 2.1 is the IETF working group's response: a clean slate that incorporates the security best practices that evolved over the previous decade.[2]
- OAuth 2.1 makes PKCE mandatory for all authorization code grants without exception — there is no carve-out for confidential server-side clients.
- The implicit grant is removed entirely in OAuth 2.1; any internal tool using implicit grant today must migrate to authorization code + PKCE before SEP-1932 ships.
- Short-lived access tokens combined with refresh token rotation are an OAuth 2.1 requirement, meaning MCP clients must handle mid-session token expiry and proactive refresh.
The changes that directly affect MCP server implementations:
PKCE is now mandatory for all grant types
PKCE (Proof Key for Code Exchange, RFC 7636[6]) was originally an optional extension for mobile apps to prevent authorization code interception attacks. OAuth 2.1 makes it mandatory for all authorization code grants, including server-to-server flows.
In practice: when an MCP client initiates an OAuth flow to get tokens for your server, it must include a code_challenge in the authorization request and a code_verifier in the token request. Your server's authorization endpoint must verify them. If your auth server doesn't implement PKCE, you're not OAuth 2.1 compliant, and SEP-1932-compliant MCP clients may refuse to proceed.
Implicit grant removed
The OAuth 2.0 implicit grant returned access tokens directly in the URL fragment after authorization. This was convenient but deeply insecure: the token appeared in browser history, server logs, and Referer headers. It's removed in OAuth 2.1. MCP clients that use implicit grant to get tokens for your server will fail with OAuth 2.1 compliant authorization servers.
Token lifetime requirements
OAuth 2.1 tightens guidance on refresh token rotation (one-time use) and recommends short-lived access tokens (minutes, not hours). This is directly relevant to MCP: a model inference session that runs for 30 minutes might hit token expiry mid-session. Your server needs to handle 401 Unauthorized responses gracefully and trigger token refresh.
<Callout type="hot"> The implicit grant removal breaks a common pattern. Many internal tools implemented MCP auth using the implicit grant because it's simple — no server-side token exchange required. If you're using implicit grant today, you need to migrate to authorization code + PKCE before SEP-1932 lands. The migration is a one-time engineering effort, but leaving it until the SEP ships means a forced migration with a hard deadline. </Callout>
Walk me through the exact sequence of messages in an OAuth 2.1 authorization code + PKCE flow for an MCP client requesting tokens for an MCP server. Include: (1) what the MCP client generates before r…
Show expected output
The expert covers: (1) The client generates a cryptographically random code_verifier (43-128 URL-safe chars), then computes code_challenge = BASE64URL(SHA256(code_verifier)). (2) Authorization request includes: response_type=code, client_id, redirect_uri, scope, state (CSRF token), code_challenge, code_challenge_method=S256. (3) Token request sends: grant_type=authorization_code, the authorization code received from the redirect, the original redirect_uri, and code_verifier. (4) The authorization server validates: BASE64URL(SHA256(code_verifier)) must equal the stored code_challenge — if this check fails, the token request is rejected with error=invalid_grant. This prevents authorization code interception: a stolen code is useless without the code_verifier that only the legitimate client holds.
Bearer tokens and why they're not enough
Before understanding DPoP, you need to understand what's wrong with Bearer tokens in the MCP context.
- Bearer tokens have no binding to the client that requested them — a stolen token is immediately usable from any machine until it expires, regardless of TLS or short expiry.
- Prompt injection is a first-class attack vector in MCP: an attacker who controls a loaded Resource can cause the model to echo the Authorization header value into a tool call response, exfiltrating the token at the application layer where TLS provides no protection.
- Long-running agentic sessions hold access tokens for 30+ minutes, making them high-value targets compared to human-interactive browser sessions.
A Bearer token is exactly what the name implies: whoever bears it wins. The HTTP spec (RFC 6750) defines Bearer tokens with no binding between the token and the client that requested it. If an attacker steals your Bearer token — by reading it from a log, from a process's memory, from a misconfigured environment variable, or via prompt injection that causes the model to echo it in a tool call — they can use it from any machine, any location, with any client, until it expires.
In traditional web app contexts, Bearer tokens are acceptable because: 1. Token expiry is typically short (1 hour) 2. Transmission is over TLS, which makes interception hard 3. Tokens are used by human-operated clients, not automated pipelines
MCP changes the threat model:
Prompt injection is a first-class attack vector. An attacker who controls a document that gets loaded as a Resource can embed instructions that cause the model to include the contents of the Authorization header in a tool call response. The model follows the instructions; the tool response containing the token is logged by the host; the attacker extracts the token from the log.
Multi-tenant HTTP servers share a token endpoint. An MCP server serving multiple organisations may accept tokens from all of them. A Bearer token issued for Organisation A's MCP client, if leaked, can be used to call Organisation B's tools if the server's validation only checks token validity, not token binding.
Long-running agentic sessions hold tokens for extended periods. A 30-minute agent workflow holds an access token for 30 minutes. Bearer tokens valid for that window are high-value targets.
DPoP addresses all three.
DPoP: how token binding works
DPoP (Demonstration of Proof-of-Possession, RFC 9449) adds a cryptographic binding between an access token and the client that requested it.[3]
- DPoP binds each access token to a client's ephemeral public key via a `cnf.jkt` (JWK Thumbprint) claim — a stolen token is useless without the matching private key that never leaves the client.
- Every API call requires a fresh DPoP proof JWT that includes `htm` (HTTP method), `htu` (full URL), `iat` (issuance time), and `jti` (unique ID), preventing both replay attacks and SSRF token-forwarding attacks.
- The server must validate six properties on every request: token validity, DPoP proof signature, key binding match, method/URL match, proof freshness (within 60s), and jti uniqueness.
Here's the mechanism:
Step 1: Key generation. The MCP client generates an ephemeral asymmetric key pair (EC P-256 or RSA 2048) at session start. The private key stays in memory; the public key is included in a DPoP-Proof JWT header.
Step 2: Token request with DPoP proof. When requesting an access token from the OAuth server, the client sends a DPoP header containing a signed JWT that includes:
- jwk: the client's public key
- htm: the HTTP method of this request (POST)
- htu: the URL of this request (token endpoint)
- iat: issuance time
- jti: a unique identifier (prevents replay)
DPoP: eyJhbGciOiJFUzI1NiIsInR5cCI6ImRwb3Arand...
Authorization: (none yet, this is the token request)
Step 3: Token issuance with binding. The OAuth server validates the DPoP proof, then issues an access token that is cryptographically bound to the client's public key. The token's cnf (confirmation) claim contains a jkt (JWK Thumbprint) — a fingerprint of the client's public key:
{
"sub": "user-alice@example.com",
"scope": "tools:read",
"exp": 1714600000,
"cnf": {
"jkt": "0ZcOCORZNYy-DWpqq30jZyJGHTN0d2HglBV3uiguA4I"
}
}
Step 4: API calls with DPoP proof. Every API call to the MCP server includes both the access token AND a new DPoP proof JWT (this one includes ath — a hash of the access token, binding the proof to the specific token):
```http POST /mcp HTTP/1.1 Authorization: DPoP eyJhbGciOiJFUzI1NiIsInR5cCI6ImRwb3Arand... DPoP: eyJhbGciOiJFUzI1NiIsInR5cCI6ImRwb3AiLCJqd2siOnsiY3... Content-Type: application/json
{"jsonrpc":"2.0","id":1,"method":"tools/call",...} ```
Step 5: Server validation. The MCP server validates:
1. The Authorization: DPoP <token> is a valid access token (signature, expiry, audience)
2. The DPoP header is a valid DPoP proof JWT
3. The DPoP proof's public key matches the cnf.jkt claim in the access token
4. The htm and htu in the DPoP proof match the current request's method and URL
5. The iat is recent (within a small window, e.g. 60 seconds — prevents replay)
6. The jti hasn't been seen before (nonce-based replay protection)
If an attacker steals the access token from a log, they can't use it. Using it requires a DPoP proof signed by the matching private key, which never left the client.
A developer argues: 'We run our MCP server over TLS and our Bearer tokens expire in 15 minutes. That's secure enough — we don't need DPoP.' Evaluate this argument. What specific attacks does DPoP prev…
Show expected output
The security engineer names: (1) Prompt injection exfiltration — TLS protects the transport, not the application layer; a prompt injection attack causes the model to emit the token value in a tool response or reasoning trace, bypassing TLS entirely. A 15-minute window is plenty for an automated exfiltration. (2) Log scraping — structured logging pipelines sometimes capture Authorization headers; a stolen token from logs can be used within the 15-minute window. DPoP makes this useless since the attacker doesn't have the private key. (3) SSRF pivot — a Server-Side Request Forgery attack that tricks the MCP server into forwarding a request to an internal service, potentially including the Authorization header. DPoP binding means even if the token is forwarded, it's only valid for the original server's URL (the `htu` claim in the DPoP proof must match).
Implementing the .well-known metadata endpoint
Before clients can authenticate against your server, they need to know where the authorization endpoints are. The MCP auth spec requires remote servers to expose an RFC 8414-compliant metadata document at /.well-known/oauth-authorization-server.[4]
Here's the minimal required document:
{
"issuer": "https://mcp.yourcompany.com",
"authorization_endpoint": "https://auth.yourcompany.com/authorize",
"token_endpoint": "https://auth.yourcompany.com/token",
"jwks_uri": "https://auth.yourcompany.com/.well-known/jwks.json",
"response_types_supported": ["code"],
"grant_types_supported": ["authorization_code", "refresh_token"],
"code_challenge_methods_supported": ["S256"],
"token_endpoint_auth_methods_supported": ["none", "client_secret_basic"],
"dpop_signing_alg_values_supported": ["ES256", "RS256"],
"scopes_supported": ["tools:read", "tools:write", "resources:read"],
"subject_types_supported": ["public"]
}
Key fields:
- dpop_signing_alg_values_supported — declares that this server accepts DPoP proofs. If absent, clients may fall back to Bearer-only.
- code_challenge_methods_supported: ["S256"] — declares PKCE with SHA-256 only (plain is insecure and should not be listed).
- scopes_supported — the tool scopes your server recognises. Chapter 5 maps these to RBAC policies.
In Python (adding to your HTTP MCP server):
```python from http.server import HTTPServer, BaseHTTPRequestHandler import json
WELL_KNOWN = { "issuer": "https://mcp.yourcompany.com", "authorization_endpoint": "https://auth.yourcompany.com/authorize", "token_endpoint": "https://auth.yourcompany.com/token", "jwks_uri": "https://auth.yourcompany.com/.well-known/jwks.json", "response_types_supported": ["code"], "grant_types_supported": ["authorization_code", "refresh_token"], "code_challenge_methods_supported": ["S256"], "dpop_signing_alg_values_supported": ["ES256"], "scopes_supported": ["tools:read", "tools:write", "resources:read"], }
class MCPHandler(BaseHTTPRequestHandler): def do_GET(self): if self.path == "/.well-known/oauth-authorization-server": body = json.dumps(WELL_KNOWN).encode() self.send_response(200) self.send_header("Content-Type", "application/json") self.send_header("Content-Length", len(body)) self.end_headers() self.wfile.write(body) else: self.send_response(404) self.end_headers() ```
My team is asking why I need to include 'dpop_signing_alg_values_supported': ['ES256'] in the .well-known/oauth-authorization-server metadata when our current MCP clients don't use DPoP yet. What is t…
Show expected output
The developer explains: Declaring dpop_signing_alg_values_supported signals that the server is DPoP-capable, enabling progressive adoption — DPoP-capable clients will use it, while legacy clients fall back to Bearer (if the server still permits both). Without the field, a SEP-1932-compliant client following metadata discovery will assume DPoP is not supported and either fall back to Bearer-only or refuse to connect entirely, depending on its policy. Including the field costs nothing: it's a metadata field, not a code change. It also future-proofs your deployment — when DPoP becomes mandatory in a spec revision, no metadata update is needed. Early declaration is how the ecosystem bootstraps a new security mechanism without a hard flag-day cutover.
Implementing DPoP validation in the MCP server
Here's a production-oriented DPoP validation implementation. This adds to the Chapter 2 echo server, extended to HTTP transport.
```python import time import hashlib import base64 import json from typing import Optional import jwt # pip install PyJWT[crypto] from cryptography.hazmat.primitives.asymmetric.ec import ECDSA from cryptography.hazmat.primitives import hashes
class DPoPValidationError(Exception): def __init__(self, message: str, error_code: str): super().__init__(message) self.error_code = error_code # e.g. "invalid_dpop_proof", "use_dpop_nonce"
def validate_dpop_proof( dpop_header: str, access_token: str, method: str, url: str, max_age_seconds: int = 60 ) -> dict: """ Validate a DPoP proof JWT per RFC 9449. Returns the decoded DPoP payload on success. Raises DPoPValidationError on any validation failure. """ try: # Decode header without verification first (to get the JWK) unverified_header = jwt.get_unverified_header(dpop_header) except jwt.DecodeError as e: raise DPoPValidationError(f"Cannot decode DPoP header: {e}", "invalid_dpop_proof")
if unverified_header.get("typ") != "dpop+jwt": raise DPoPValidationError("DPoP JWT must have typ=dpop+jwt", "invalid_dpop_proof")
jwk = unverified_header.get("jwk") if not jwk: raise DPoPValidationError("DPoP JWT must contain jwk in header", "invalid_dpop_proof")
return payload
def build_www_authenticate_header(error: str, error_desc: str) -> str: """Build a RFC 9449-compliant WWW-Authenticate header for DPoP failures.""" return ( f'DPoP realm="mcp-server", ' f'error="{error}", ' f'error_description="{error_desc}", ' f'algs="ES256"' )
def extract_dpop_token(auth_header: str) -> Optional[str]: """Extract access token from 'DPoP <token>' Authorization header.""" if not auth_header or not auth_header.startswith("DPoP "): return None return auth_header[5:].strip() ```
Wiring into the MCP request handler:
```python import sys import time
def handle_mcp_request(auth_header: str, dpop_header: str, request_url: str, msg: dict) -> dict: """ Validates auth before processing MCP message. Returns a JSON-RPC error response if auth fails. """ access_token = extract_dpop_token(auth_header) if not access_token: return { "jsonrpc": "2.0", "id": msg.get("id"), "error": {"code": -32000, "message": "Missing or invalid Authorization header. Expected: DPoP <token>"} }
try: dpop_payload = validate_dpop_proof( dpop_header=dpop_header, access_token=access_token, method="POST", url=request_url ) except DPoPValidationError as e: # Log the failure to stderr as structured JSON for audit audit_entry = { "ts": time.time(), "event": "auth_failure", "error_code": e.error_code, "error": str(e), "method": msg.get("method"), } print(json.dumps(audit_entry), file=sys.stderr) return { "jsonrpc": "2.0", "id": msg.get("id"), "error": {"code": -32001, "message": str(e), "data": {"error_code": e.error_code}} }
audit_entry = { "ts": time.time(), "event": "tool_call", "sub": token_sub, "method": msg.get("method"), "tool": msg.get("params", {}).get("name"), "args_hash": hashlib.sha256( json.dumps(msg.get("params", {}).get("arguments", {}), sort_keys=True).encode() ).hexdigest()[:16] } print(json.dumps(audit_entry), file=sys.stderr)
Review this DPoP validation implementation. The code uses an in-memory set (_used_jti) to prevent JTI replay. What are the three most important production problems with this approach, and how would yo…
Show expected output
The engineer identifies: (1) In-memory JTI store is not shared across server instances — in a horizontally-scaled deployment, a replay attack can succeed by sending the duplicate JTI to a different instance. Fix: use Redis with TTL equal to the DPoP proof max_age window. (2) The set grows unboundedly — in production, old JTIs from minutes ago should be evicted. Fix: use a TTL-keyed store. (3) Server restart loses all JTIs — a replay of recently-used JTIs succeeds after a restart. Fix: persist the JTI store to durable storage, or accept this as a known trade-off for stateless deployments and document it.
Hands-on exercise
Add DPoP validation to the Chapter 2 echo server.
Goal: Extend the Python echo server to run as an HTTP server. Add DPoP validation on every tools/call request. Return a structured 401 on any auth failure. Emit one structured JSON audit log line per validated call.
Steps:
- Copy the DPoP validation functions above into your echo server.
- Add an HTTP endpoint (
POST /mcp) that validates DPoP before dispatching. The critical 401 path must include aWWW-Authenticateheader:
```python class MCPHTTPHandler(BaseHTTPRequestHandler): def do_POST(self): if self.path != "/mcp": self.send_response(404); self.end_headers(); return
auth_header = self.headers.get("Authorization", "") dpop_header = self.headers.get("DPoP", "") length = int(self.headers.get("Content-Length", 0)) body = json.loads(self.rfile.read(length))
access_token = extract_dpop_token(auth_header) if not access_token or not dpop_header: self.send_response(401) self.send_header( "WWW-Authenticate", 'DPoP realm="mcp-server", algs="ES256"' ) self.send_header("Content-Type", "application/json") self.end_headers() self.wfile.write(json.dumps({ "jsonrpc": "2.0", "id": body.get("id"), "error": {"code": -32000, "message": "DPoP authorization required"} }).encode()) return
try: validate_dpop_proof(dpop_header, access_token, "POST", f"http://localhost:8080/mcp") except DPoPValidationError as e: self.send_response(401) self.send_header("WWW-Authenticate", build_www_authenticate_header(e.error_code, str(e))) self.send_header("Content-Type", "application/json") self.end_headers() self.wfile.write(json.dumps({ "jsonrpc": "2.0", "id": body.get("id"), "error": {"code": -32001, "message": str(e)} }).encode()) return
- Add the
/.well-known/oauth-authorization-serverendpoint from the earlier section.
- Add the
GEThandler for: - ```
- GET /.well-known/oauth-authorization-server
- → 200 + WELL_KNOWN JSON
- ```
Testing (using curl to simulate a request with a fake token — DPoP validation will fail, confirming the 401 path works):
```bash # Start your server on port 8080 python3 echo_server_http.py &
Verification criteria:
- .well-known returns valid JSON with dpop_signing_alg_values_supported
- Unauthenticated tools/call returns HTTP 401 with WWW-Authenticate: DPoP ... header
- Audit log (stderr) contains one JSON line per request with event, ts, and error_code fields
Estimated time: 20 minutes.
What's next
In Chapter 5, we take the auth-enabled server from this chapter and put it behind a gateway. You'll configure RBAC so that tools:read scope can only call read tools and tools:admin scope is required for write tools. You'll set up structured audit logging that meets a SOC 2 audit template, and you'll deploy with zero downtime using rolling restarts behind the gateway.
References cited
[1]: MCP 2026 Roadmap — https://blog.modelcontextprotocol.io/posts/2026-mcp-roadmap/ · retrieved 2026-04-30
[2]: The OAuth 2.1 Authorization Framework (draft-ietf-oauth-v2-1-15) — https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-15 · retrieved 2026-04-30
[3]: RFC 9449: OAuth 2.0 Demonstrating Proof of Possession (DPoP) — https://datatracker.ietf.org/doc/html/rfc9449 · retrieved 2026-04-30
[4]: RFC 8414: OAuth 2.0 Authorization Server Metadata — https://datatracker.ietf.org/doc/html/rfc8414 · retrieved 2026-04-30
[5]: Model Context Protocol Specification — https://spec.modelcontextprotocol.io/ · retrieved 2026-04-30
[6]: RFC 7636: Proof Key for Code Exchange by OAuth Public Clients — https://datatracker.ietf.org/doc/html/rfc7636 · retrieved 2026-04-30
- MCP Authorization Specification — https://spec.modelcontextprotocol.io/specification/2025-03-26/basic/authorization/ · retrieved 2026-04-30
References
- https://spec.modelcontextprotocol.io/
- https://spec.modelcontextprotocol.io/specification/2025-03-26/basic/authorization/
- https://datatracker.ietf.org/doc/html/rfc9449
- https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-15
- https://blog.modelcontextprotocol.io/posts/2026-mcp-roadmap/
- https://datatracker.ietf.org/doc/html/rfc8414
Gateways, audit logs, and shipping to a 1,000-user team
An MCP gateway is a reverse proxy specialized for the Model Context Protocol that handles server discovery, role-based access control, per-user rate limiting, and structured audit logging — sitting between MCP clients and one or more upstream MCP servers so that none of those concerns need to live inside individual server implementations. The concept was formalized in the 2026 MCP specification roadmap[1], which identified multi-server orchestration and centralized policy enforcement as the top two production gaps teams were working around manually. By Q2 2026, at least three open-source gateway implementations existed, each taking the same approach: validate the DPoP token once at the edge, enforce RBAC scopes before forwarding, and write one JSON Lines audit entry per tool call.
> Prerequisites: Chapters 1–4 — specifically the DPoP-enabled server you built in Chapter 4. You should have a running MCP server that validates DPoP-bound access tokens and returns structured 401 errors.
>
> Time: 60 minutes
>
> What you'll be able to do: By the end of this chapter, you will have deployed your Chapter 4 server behind a gateway, configured RBAC with tools:read and tools:admin scopes, produced SOC 2-compatible audit logs, and can describe the five failure modes that end production MCP deployments.
Key facts
- The MCP specification's
.well-known/mcp.jsonendpoint (analogous to OAuth's.well-known/oauth-authorization-serverfrom Chapter 4) allows gateways to autodiscover server capabilities, available tools, and required auth scopes without manual configuration.[2] - As of the 2026 MCP roadmap, gateway-level RBAC using OAuth scopes (
tools:read,tools:admin) is the recommended pattern for multi-tenant deployments rather than embedding authorization logic inside individual servers.[1] - JSON Lines (JSONL) — one JSON object per newline — is the de-facto format for MCP audit logs: it is streamable, grep-able, and directly ingestible by every major observability backend (Loki, Datadog, Splunk, CloudWatch Logs).[2]
- MCP servers designed for horizontal scaling must be stateless across requests: session affinity (sticky sessions) is a design smell that prevents zero-downtime rolling deployments.
- The five most common production failure modes in MCP deployments are: token expiry mid-session, gateway single-point-of-failure, session state leaking into horizontally-scaled servers, audit log saturation, and rate-limit false positives under burst load.
The contrarian premise: gateways on day one, not day 100
Most engineering teams introduce a gateway after they hit a problem — usually when security asks "who called that tool last Tuesday?" and no one has an answer. By then, the audit trail is gone, RBAC is bolted on as an afterthought, and the refactor costs a sprint.
- Setting up an OSS MCP gateway takes under two hours and provides server discovery, token validation, RBAC enforcement, and audit logging from day one — retrofitting these after deployment costs far more.
- The gateway is transparent to MCP clients: it receives and forwards valid JSON-RPC frames without the client needing to know or care that a gateway is in the path.
- Adding a gateway to an existing deployment requires no changes to server or client code — the wire protocol is unchanged.
The argument for gateway-first is economic, not architectural. Setting up mcp-gateway (the OSS option covered in this chapter) takes under two hours. It gives you server discovery, token validation, RBAC enforcement, and a JSON Lines audit stream from the first deployment. Compare that to the cost of retrofitting all of that after your server is in production and twenty other teams are calling it.
The wire protocol you learned in Chapter 2 does not change when you add a gateway. The gateway is transparent to the MCP client: it receives valid JSON-RPC frames, forwards them upstream, and returns the upstream response. The client doesn't know or care that a gateway is in the path. That transparency is what makes the gateway-first pattern possible: you can add it to an existing deployment without touching the server or client code.
Gateway topology: what goes where
MCP Client (Claude Desktop, IDE plugin, your agent)
│ JSON-RPC over HTTP (Streamable HTTP transport)
▼
┌─────────────────────────────────────────────────────┐
│ MCP Gateway │
│ ┌─────────────┐ ┌──────────────┐ ┌───────────┐ │
│ │ DPoP check │ │ RBAC policy │ │ Audit log │ │
│ └─────────────┘ └──────────────┘ └───────────┘ │
│ ┌──────────────┐ │
│ │ Rate limiter │ │
│ └──────────────┘ │
└──────────────────────────┬──────────────────────────┘
│ JSON-RPC (forwarded)
┌────────────┼────────────┐
▼ ▼ ▼
Server A Server B Server C
(GitHub) (Jira) (Slack)
The gateway is the single ingress point for all MCP traffic. It does four things before forwarding any request:
- The gateway handles four pre-forwarding steps in sequence: DPoP token validation, RBAC scope check, rate limiting, and audit log write — none of these concerns need to live inside individual server implementations.
- The `scopes_required` map in `.well-known/mcp.json` is server-declared RBAC policy: the gateway reads it and enforces per-method and per-tool-name scope requirements without requiring custom gateway configuration per server.
- The gateway polls `.well-known/mcp.json` on startup and on a configurable interval (typically 5 minutes), so RBAC policy updates propagate automatically when the server's discovery document changes.
- Token validation: verify the DPoP proof JWT and access token (as you wired in Chapter 4)
- RBAC enforcement: check the token's scopes against the requested tool
- Rate limiting: apply per-user or per-client token bucket limits
- Audit logging: write one JSONL entry with request metadata before the upstream call
After the upstream server responds, the gateway may also sanitize the response (strip raw secrets from tool outputs) and write a second audit entry with the result status and duration.
Server discovery via .well-known/mcp.json
For the gateway to know which upstream servers exist and what they expose, the MCP spec defines a discovery mechanism: a server exposes a /.well-known/mcp.json document at its base URL.[2] The gateway polls this on startup and on a configurable interval (default: 5 minutes in most implementations).
A minimal /.well-known/mcp.json looks like this:
{
"schema_version": "2025-03-26",
"server_name": "github-mcp",
"description": "GitHub integration — list repos, read files, create PRs",
"capabilities": {
"tools": true,
"resources": true,
"prompts": false
},
"scopes_required": {
"tools/list": ["tools:read"],
"tools/call": ["tools:read"],
"tools/call#create_pr": ["tools:admin"]
},
"auth": {
"type": "oauth2_dpop",
"metadata_url": "https://auth.example.com/.well-known/oauth-authorization-server"
}
}
The scopes_required map is the key field: it tells the gateway which OAuth scopes are needed per method (and optionally per tool name, using the #tool_name suffix). The gateway uses this map to enforce RBAC without needing custom configuration per server — the policy is declared by the server itself.
Configuring mcp-gateway
mcp-gateway is the reference OSS implementation. Install it:
pip install mcp-gateway # Python variant
# or
npm install -g @mcp/gateway # Node variant
The gateway is configured with a single YAML file:
```yaml # gateway.yaml listen: ":8080"
auth: jwks_uri: "https://auth.example.com/.well-known/jwks.json" audience: "mcp-github" dpop_required: true
servers: - name: github upstream: "http://localhost:9000" discovery: "http://localhost:9000/.well-known/mcp.json" refresh_interval_s: 300
rate_limits: default: requests_per_minute: 60 burst: 10 scopes: tools:admin: requests_per_minute: 20 burst: 5
audit: output: "/var/log/mcp/audit.jsonl" fields: - timestamp - request_id - user_sub - tool_name - args_hash - result_status - duration_ms - gateway_id ```
Start the gateway:
mcp-gateway start --config gateway.yaml
The gateway will discover the upstream server's capabilities via .well-known/mcp.json, configure RBAC from the scopes_required map, and begin listening on port 8080.
You are an SRE reviewing an mcp-gateway YAML config. Identify any missing security-critical fields in this config:\n\nlisten: ':8080'\nauth:\n jwks_uri: 'https://auth.example.com/.well-known/jwks.jso…
Show expected output
The model should flag: (1) dpop_required is missing — tokens would be accepted as plain bearer tokens; (2) discovery is missing — the gateway won't auto-update RBAC when the server's .well-known changes; (3) the rate limit of 100 rpm is high with no burst cap — easier to flood.
RBAC: scopes, tools, and the least-privilege rule
RBAC in MCP is scope-based: the OAuth access token carries a set of scopes, and the gateway checks them against the scopes_required map from .well-known/mcp.json before forwarding the request.
- The two canonical MCP scopes are `tools:read` (list and call read-only tools, read resources) and `tools:admin` (all of the above plus write and destructive tools).
- The `scopes_required` map supports per-tool granularity using the `#tool_name` suffix — a single method like `tools/call` can require different scopes for different tools.
- Rate limits for `tools:admin` should be tighter than for `tools:read` because write operations are inherently more impactful per call — a runaway admin-scope agent causes more damage per request.
The two canonical scopes are:
| Scope | What it allows |
|---|---|
tools:read | tools/list, tools/call on read-only tools, resources/read |
tools:admin | All of the above + tools/call on write/destructive tools (e.g., create_pr, delete_branch) |
The mapping in scopes_required lets you be surgical:
"scopes_required": {
"tools/list": ["tools:read"],
"tools/call": ["tools:read"],
"tools/call#create_pr": ["tools:admin"],
"tools/call#delete_branch": ["tools:admin"]
}
A user with only tools:read can call list_repos and read_file, but gets a 403 Forbidden when they try to call create_pr. The gateway enforces this transparently — the server doesn't need to check scopes itself.
Assigning scopes at the authorization server
When your auth server issues tokens (from Chapter 4's .well-known/oauth-authorization-server), it grants scopes based on user role. A simple mapping:
| User role | Granted scopes |
|---|---|
| Developer | tools:read |
| Senior Dev / Ops | tools:read tools:admin |
| CI/CD service account | tools:read |
| Security auditor | tools:read (read-only, audit view) |
This is the least-privilege principle applied to MCP: you grant the minimum scope needed for the job. A CI/CD pipeline that only reads file contents should never have tools:admin.
Structured audit logging for SOC 2
A SOC 2 Type II audit requires that you can answer five questions about any system action:
- Audit logs must record who, what, when, with what, and what happened — MCP gateway audit entries cover all five using fields from the DPoP token and the JSON-RPC request.
- Raw tool arguments must never appear in audit logs; hash them (SHA-256 of serialized JSON args) to enable correlation without logging PII or secrets that tool arguments frequently contain.
- Use `user_sub` from the DPoP token as the identity field, not a header value — it is cryptographically tied to the client's private key and cannot be spoofed.
- Who performed it (identity, non-repudiable)
- What they did (action and target)
- When they did it (timestamp, UTC, sub-second)
- With what (parameters — or at minimum a hash of parameters to avoid logging PII)
- What happened (result: success, failure, partial)
MCP gateway audit logs answer all five. Here's the schema:
{
"timestamp": "2026-04-30T14:23:11.847Z",
"request_id": "req_01HZXKV2G3FMRNT8QKJW5P",
"gateway_id": "gw-prod-us-east-1-01",
"user_sub": "user|8f3d2a1c",
"client_id": "claude-desktop",
"tool_name": "create_pr",
"args_hash": "sha256:e3b0c44298fc1c149afb",
"result_status": "success",
"duration_ms": 342,
"http_status": 200,
"scope_used": "tools:admin",
"upstream": "github"
}
Key design decisions in this schema:
- `args_hash` not
args: never log raw tool arguments. Tool arguments frequently contain secrets (API keys passed as context), PII (user-provided queries), or IP-sensitive business data. Hash them for audit correlation without data exposure. SHA-256 of the serialized JSON args is sufficient. - `user_sub` from the DPoP token, not from a header. This is non-repudiable: the subject claim in a DPoP-bound access token is cryptographically tied to the client's private key.
- `request_id` is a gateway-generated ULID (Universally Unique Lexicographically Sortable Identifier) — not a UUID. ULIDs sort chronologically, which makes log queries dramatically faster when you're scanning a time range.
- `duration_ms` covers gateway-to-upstream round-trip, not end-to-end client latency. This lets you distinguish slow tool execution from slow network.
Adding the server-side audit hook
Even with a gateway, add a thin audit hook to your server for defense-in-depth — logs that capture what the server actually processed, not just what the gateway forwarded:
```python import json import time import hashlib import sys from datetime import datetime, timezone
def audit_log(tool_name: str, args: dict, result_status: str, user_sub: str, duration_ms: float): entry = { "timestamp": datetime.now(timezone.utc).isoformat(), "source": "mcp-server", "tool_name": tool_name, "args_hash": "sha256:" + hashlib.sha256( json.dumps(args, sort_keys=True).encode() ).hexdigest()[:20], "result_status": result_status, "user_sub": user_sub, "duration_ms": round(duration_ms, 2), } # JSON Lines: one object per line, to stderr (not stdout — stdout is the MCP channel) print(json.dumps(entry), file=sys.stderr, flush=True) ```
> Important: MCP servers using stdio transport write audit logs to stderr, not stdout. stdout is the MCP JSON-RPC channel; writing anything to it other than valid JSON-RPC responses will corrupt the stream. The wire protocol chapter explains why.
I have an MCP server that logs audit entries to stderr as JSON Lines. Write a one-liner bash command that tails the audit log file at /var/log/mcp/audit.jsonl, filters for entries where tool_name is '…
Show expected output
tail -f /var/log/mcp/audit.jsonl | jq 'select(.tool_name == \
You are an MCP gateway configured with this RBAC policy:\n\n tools:read → tools/list, tools/call (read tools)\n tools:admin → all tools\n\nA request arrives with scope 'tools:read' for tool 'create_…
Show expected output
The model should return something like:
{
'jsonrpc': '2.0',
'id': '<request-id>',
'error': {
'code': -32000,
'message': 'Insufficient scope',
'data': {
'required_scope': 'tools:admin',
'granted_scope': 'tools:read',
'tool': 'create_pr'
}
}
}
Note: -32000 is the JSON-RPC application error range. The error.data object gives the client enough information to request elevated scope.Rate limiting: protecting your servers and your budget
Rate limiting in an MCP gateway serves two purposes: protecting upstream servers from accidental (or intentional) flooding, and protecting your LLM API budget from runaway agents.
The token bucket algorithm is the right choice for MCP:
- Each user starts with
bursttokens - Tokens replenish at
requests_per_minute / 60tokens per second - Each request consumes one token
- When the bucket is empty, the gateway returns
429 Too Many Requestswith aRetry-Afterheader
The mcp-gateway config from earlier sets:
rate_limits:
default:
requests_per_minute: 60
burst: 10
scopes:
tools:admin:
requests_per_minute: 20
burst: 5
tools:admin gets a tighter limit because write operations (creating PRs, deleting branches) are inherently more impactful per call. A runaway agent with admin scope that makes 20 calls/minute is more dangerous than one making 60 read calls/minute.
The Retry-After contract
When the gateway returns 429, MCP clients should honor the Retry-After header:
``` HTTP/1.1 429 Too Many Requests Content-Type: application/json Retry-After: 14
{ "jsonrpc": "2.0", "id": "abc123", "error": { "code": -32029, "message": "Rate limit exceeded", "data": { "retry_after_seconds": 14, "limit": "60/minute", "scope": "tools:read" } } } ```
Well-behaved MCP clients (Claude Desktop, the Anthropic Python SDK) will back off and retry after the specified interval. Badly-behaved clients that retry immediately will hit the limit again and extend their backoff window.
The five production failure modes
These are the five patterns that actually end production MCP deployments. Each has a mitigation that's straightforward once you know what to look for.
Failure mode 1: Token expiry mid-session
What happens: An access token issued at session start expires (typically 15–60 minutes for DPoP tokens) while the model is mid-conversation. The next tools/call returns 401. The client doesn't know how to refresh, so the session dies silently — the user sees the tool return nothing, not an error.
Mitigation: MCP clients must implement proactive token refresh — refresh the token when expires_in - current_time < 60s, not reactively on 401. Your server and gateway should return the WWW-Authenticate: Bearer realm="...", error="invalid_token" header on 401 with enough detail for the client to trigger refresh. Include token_expiry in the audit log so you can detect sessions that die at the same time as token expiry.
Failure mode 2: Gateway single point of failure
What happens: You run one gateway instance. It crashes at 2 AM. All MCP traffic fails for 45 minutes until someone restarts it. You don't notice until users complain.
Mitigation: Run at least two gateway instances behind a load balancer (Nginx, HAProxy, or your cloud provider's NLB). Gateways are stateless — they validate tokens, check RBAC, forward requests. No session state needs to be shared between instances. A two-instance active-active setup with health checks is sufficient for most deployments under 1,000 users. Add a /health endpoint to your gateway config and wire it to your load balancer.
Failure mode 3: Session state leaking into horizontal scaling
What happens: A developer adds in-memory caching to their MCP server — perhaps caching a GitHub API token or a user's last-read file. Works fine with one instance. When you add a second instance behind the gateway, requests load-balance randomly between them, and the cache miss rate doubles while users see inconsistent behavior (tool succeeds on one request, fails on the next identical request).
Mitigation: MCP servers must be stateless across requests. The wire protocol is inherently stateless at the transport level — each JSON-RPC request carries all the context needed to respond. If you need caching, use an external cache (Redis, Memcached) keyed on the user_sub + tool arguments hash, with a short TTL (30–120 seconds). Never use in-process state for user-specific data.
Failure mode 4: Audit log storage saturation
What happens: Your MCP server is generating one audit log entry per tool call. At 1,000 users making 60 calls/minute each, that's 60,000 lines/minute. Uncompressed JSONL at ~300 bytes/line is 18 MB/minute, 26 GB/day. Your /var/log partition fills in 24 hours and the server crashes.
Mitigation: Never write audit logs to a local file in production. Stream them to an observability backend from the start: Loki (if you're running Grafana), Datadog Logs, CloudWatch Logs, or Splunk. The mcp-gateway supports a sink configuration:
audit:
sink: loki
loki_push_url: "http://loki:3100/loki/api/v1/push"
loki_labels:
app: mcp-gateway
env: production
If you must use local files (air-gapped environments), configure logrotate with daily rotation, 7-day retention, and compress + delaycompress. But stream first.
Failure mode 5: Rate-limit false positives under burst load
What happens: A legitimate user runs a script that makes 15 calls in quick succession (processing a batch of files). The token bucket is set to burst: 10, so the last 5 calls return 429. The user assumes the server is broken and files a support ticket. The script crashes mid-batch and leaves resources in an inconsistent state.
Mitigation: Design burst headroom for legitimate use cases. A burst of 10 is appropriate for interactive use; a burst of 50–100 is appropriate if your use case includes batch operations. Differentiate rate limits by OAuth scope or client_id:
rate_limits:
clients:
claude-desktop:
burst: 10 # Interactive — small burst
ci-pipeline:
burst: 100 # Batch — large burst, same per-minute ceiling
Identify legitimate batch clients by their client_id claim in the token and give them a higher burst allowance without raising the per-minute ceiling.
You are reviewing a production MCP audit log stream. Here are three consecutive JSONL lines:\n\n{\
Show expected output
The third entry shows delete_branch succeeding for a user — but if RBAC is configured, this should only succeed if the user has tools:admin scope. The log doesn't record which scope was used to authorize the call, making it impossible to audit whether RBAC was enforced. Two fields to add: (1) scope_used — the actual scope present in the token at call time; (2) rbac_policy_version — the version of the .well-known/mcp.json that the RBAC check ran against. With scope_used, a SIEM can flag calls to admin tools where scope_used is 'tools:read', indicating a gateway misconfiguration.
Horizontal scaling and zero-downtime deployments
When you're ready to scale from one server instance to a team of 1,000, two properties must hold:
1. Servers must be stateless: covered above. Verify by running two instances simultaneously and sending alternating requests to each. If any response depends on which instance received the previous request, you have leaked state.
2. Rolling deployments must be possible: the gateway must support routing traffic to new server versions before the old ones shut down. mcp-gateway supports weighted upstream routing:
servers:
- name: github-v2
upstream: "http://server-v2:9000"
weight: 90
- name: github-v1
upstream: "http://server-v1:9000"
weight: 10
Start with 10% traffic on the new version, watch the error rate and p99 latency in your audit logs, then ramp to 100% and drain v1. This is a standard blue-green pattern applied to MCP.
Hands-on exercise: gateway + RBAC + audit logs end-to-end
Goal: deploy the DPoP-enabled server from Chapter 4 behind mcp-gateway. Configure RBAC. Verify that tools:read users can list and call read tools but are rejected from admin tools. Capture one audit log line per call.
Setup (15 minutes):
```bash # 1. Install mcp-gateway pip install mcp-gateway
auth: jwks_uri: "http://localhost:8000/.well-known/jwks.json" audience: "mcp-local-dev" dpop_required: true
servers: - name: my-mcp-server upstream: "http://localhost:9000" discovery: "http://localhost:9000/.well-known/mcp.json"
rate_limits: default: requests_per_minute: 60 burst: 10
audit: output: "/tmp/mcp-audit.jsonl" fields: [timestamp, request_id, user_sub, tool_name, args_hash, result_status, duration_ms] EOF
Test RBAC (10 minutes):
```bash # Mint a tools:read token (use your ch04 auth server or a local mock) READ_TOKEN=$(./mint-token.sh --scope tools:read --sub "test-user-read")
Verify audit logs (5 minutes):
```bash # Watch the audit log in real-time tail -f /tmp/mcp-audit.jsonl | jq '.'
Success criteria:
- tools/list returns 200 with the read-only token
- delete_branch call returns 403 with required_scope: tools:admin
- Audit log has one entry per request with user_sub, tool_name, and result_status
- Log entries are valid JSONL (parseable by jq)
Estimated time: 30 minutes including setup.
What's next
This is the final chapter of the course. You've now built every layer of a production MCP deployment:
- Chapter 1: Why MCP exists and the N×M problem it solves
- Chapter 2: The wire protocol — JSON-RPC frames, the initialize lifecycle, stdio vs. HTTP transport
- Chapter 3: Tools, Resources, and Prompts — the three primitives and the decision rule
- Chapter 4: OAuth 2.1 + DPoP — auth that survives a security audit
- Chapter 5 (this chapter): Gateways, RBAC, audit logs, and five failure modes you can now prevent
The capstone project takes everything you've built and assembles it into a single GitHub integration MCP server: list_repos (Tool), read_file (Resource with URI templating), generate_commit_message (Prompt), DPoP auth, gateway config, and 10 tests. You should be able to complete it in under 60 minutes.
References
[1]: MCP 2026 Roadmap — https://blog.modelcontextprotocol.io/posts/2026-mcp-roadmap/ · retrieved 2026-04-30 [2]: MCP Specification (2025-03-26) — https://spec.modelcontextprotocol.io/ · retrieved 2026-04-30 [3]: RFC 9449: DPoP — Demonstration of Proof of Possession — https://datatracker.ietf.org/doc/html/rfc9449 · retrieved 2026-04-30 [4]: RFC 8414: OAuth 2.0 Authorization Server Metadata — https://datatracker.ietf.org/doc/html/rfc8414 · retrieved 2026-04-30 [5]: JSON Lines specification — https://jsonlines.org/ · retrieved 2026-04-30 [6]: OAuth 2.1 Draft (draft-ietf-oauth-v2-1-12) — https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-12 · retrieved 2026-04-30